
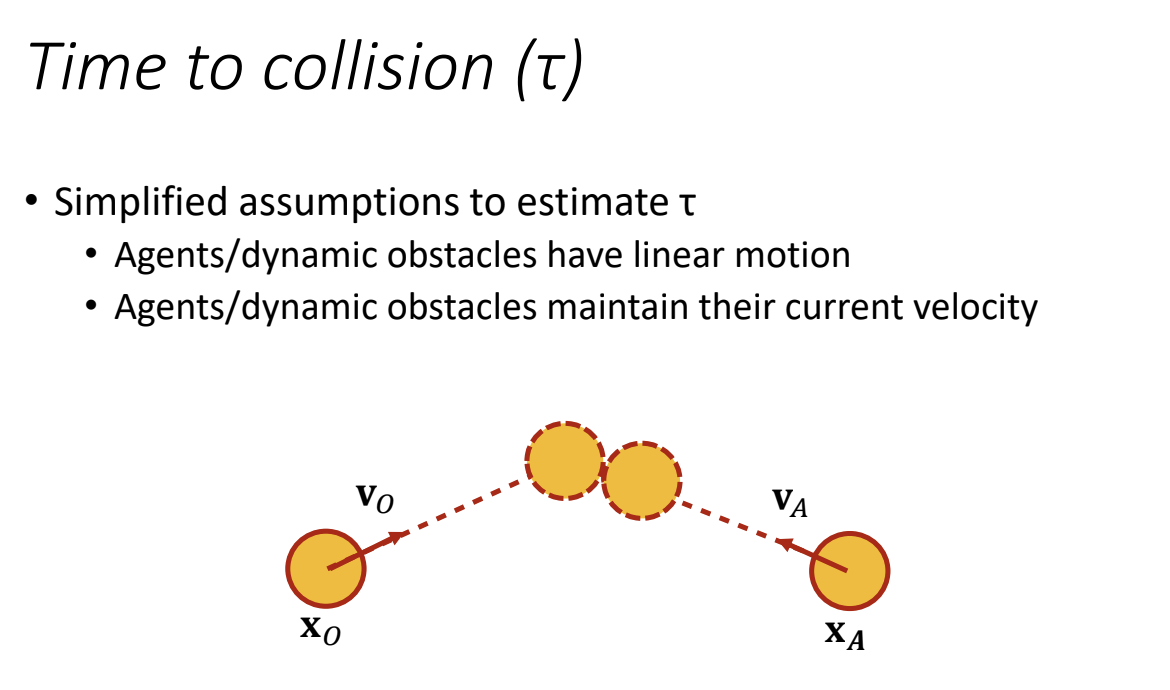
Overview of the Slide
The slide starts by stating that, implementation-wise, most models for local collision avoidance can be classified into three categories. These methods are different ways a robot can process sensor data and decide how to move to avoid obstacles while heading toward a goal. Let’s dive into each one.
1. Force-Based (Related to Artificial Potential Fields)
Explanation
- What It Is: This method treats the robot’s navigation like a physics problem. The robot is modeled as a particle moving under the influence of “forces”:
- Attractive Force: Pulls the robot toward its goal, like a magnet.
- Repulsive Force: Pushes the robot away from obstacles, based on their proximity.
- The robot calculates the net force (attractive + repulsive) and moves in that direction.
- How It Works:
- Imagine the goal as a “low potential” point (like a valley) and obstacles as “high potential” points (like hills). The robot moves “downhill” toward the goal while avoiding the hills.
- Mathematically, the potential field is a function U(x), where xx is the robot’s position. The force is the negative gradient of this potential: $F=-\Delta U$.
- Example: If an obstacle is 1 meter away, it might exert a repulsive force proportional to $\frac{1}{d^2}$ (where ddis the distance), while the goal exerts a constant attractive force.
- References:
- Reynolds 1987: Craig Reynolds introduced concepts like “steering behaviors” for autonomous agents, which influenced force-based navigation.
- Helbing et al. 2000: Dirk Helbing applied similar ideas to model pedestrian dynamics (e.g., how people avoid collisions while walking).
- Karamouzas et al. 2014: Ioannis Karamouzas extended force-based methods for multi-agent systems, like robot swarms.
Connection to Local Collision Avoidance
- This is the same Potential Fields method I mentioned in my previous response. It’s reactive, meaning the robot adjusts its path in real-time based on sensor data (e.g., from LiDAR or ultrasonic sensors).
- Pros: Simple to implement, intuitive, and works well in uncluttered environments.
- Cons: Can get stuck in “local minima” (e.g., the robot might oscillate between two obstacles or stop prematurely if forces balance out).
Example
Imagine a robot in a room with a goal on the opposite side and a table in the middle. The goal pulls the robot straight, but as it approaches the table, the table’s repulsive force pushes the robot to the side. The robot follows the combined force, curving around the table to reach the goal.
2. Velocity-Based (Directly Plan in the Velocity Space)
Explanation
- What It Is: Instead of thinking in terms of forces, this method focuses on the robot’s velocity (speed and direction). The robot evaluates a set of possible velocities and picks one that:
- Avoids obstacles.
- Moves the robot closer to the goal.
- How It Works:
- The robot operates in a “velocity space,” where each point represents a possible velocity (e.g., (v,ω), where vv is linear speed and ωω is angular speed for a differential-drive robot).
- It uses sensor data to identify “forbidden” velocities (those that would lead to a collision).
- It then selects a “safe” velocity that also aligns with the goal direction, often using a cost function (e.g., minimize distance to goal while maximizing obstacle clearance).
- References:
- Fox et al. 1997: Dieter Fox introduced the Dynamic Window Approach (DWA), a popular velocity-based method (which I mentioned earlier).
- Fiorini and Shiller 1998: Paolo Fiorini and Zvi Shiller developed the concept of “velocity obstacles,” where the robot avoids velocities that would lead to collisions with moving obstacles.
- van den Berg et al. 2011: Jur van den Berg extended velocity-based methods for multi-robot systems with the “Reciprocal Velocity Obstacles (RVO)” framework.
Connection to Local Collision Avoidance
- The Dynamic Window Approach (DWA) from my earlier response is a velocity-based method. It’s widely used in ROS (Robot Operating System) navigation stacks.
- Velocity Obstacles (VO): This concept models the robot and obstacles as moving objects. For each obstacle, the robot calculates a set of velocities that would lead to a collision (the “velocity obstacle”) and avoids those.
- Pros: Naturally handles dynamic environments (e.g., moving obstacles) and robot dynamics (e.g., acceleration limits).
- Cons: Can be computationally expensive, especially with many obstacles, and may struggle in very tight spaces.
Example
A robot is moving at 0.5 m/s toward a goal, but a person walks in front of it. The robot evaluates its velocity options: continuing at 0.5 m/s would cause a collision, but slowing to 0.2 m/s and turning 30 degrees left avoids the person. It picks the latter velocity.
3. Control-Based (Directly Plan in the Control Space)
Explanation
- What It Is: This method focuses on the robot’s control inputs (e.g., motor commands) rather than forces or velocities. It directly plans a sequence of control actions to avoid obstacles and reach the goal.
- How It Works:
- The robot operates in a “control space,” where each point represents a control input (e.g., $(u1,u2)$, where u1 and u2 might be voltages to two motors).
- It predicts the outcome of each control input over a short time horizon (e.g., “If I apply this voltage, where will I be in 0.5 seconds?”).
- It selects the control input that avoids collisions and moves toward the goal, often using optimization techniques like Model Predictive Control (MPC).
- References:
- Wilkie et al. 2009: David Wilkie explored control-based planning for autonomous vehicles.
- Williams et al. 2016: Brian Williams applied control-based methods to drones, focusing on trajectory optimization.
- Davis et al. 2020: Joshua Davis used control-based approaches for manipulators (robotic arms) to avoid obstacles during motion.
Connection to Local Collision Avoidance
- This method is less reactive than force-based or velocity-based approaches and more predictive. It’s often used in systems where precise control is critical, like robotic arms or drones.
- Model Predictive Control (MPC): A common control-based technique. MPC optimizes a sequence of control inputs over a time horizon, considering constraints (e.g., avoid obstacles, respect motor limits).
- Pros: Handles complex robot dynamics and constraints well, can plan smoother paths.
- Cons: Computationally intensive, requires an accurate model of the robot’s dynamics.
Example
A drone needs to fly through a narrow gap. Instead of reacting to obstacles in real-time, it plans a sequence of rotor speeds (control inputs) that will guide it through the gap without crashing, predicting its trajectory over the next 2 seconds.
Comparing the Three Methods
| Method | Core Idea | Strengths | Weaknesses |
|---|---|---|---|
| Force-Based | Navigate using attractive/repulsive forces | Simple, intuitive, fast | Local minima, oscillatory behavior |
| Velocity-Based | Plan in velocity space | Handles dynamic obstacles, robot dynamics | Computationally heavy, may fail in tight spaces |
| Control-Based | Plan in control space | Precise, smooth trajectories | Computationally intensive, needs accurate model |

Let’s unpack the slide you provided on Local Navigation Methods, which classifies local collision avoidance models based on behavior-wise categories: Reactive and Predictive. This approach focuses on how robots behave when avoiding obstacles, drawing inspiration from natural systems like particles, flocking, or human behavior. I’ll explain each category, connect it to the earlier discussion on implementation-wise methods (Force-Based, Velocity-Based, Control-Based), and provide context to help you learn.
Overview of the Slide
The slide suggests that local collision avoidance models can be categorized by the behavior they exhibit, rather than just how they’re implemented (as in the previous slide). This perspective emphasizes the robot’s decision-making style—whether it reacts instantly to its environment or predicts future states. Let’s dive into each category.
1. Reactive
Explanation
- What It Is: Reactive methods involve the robot responding immediately to its current sensor data without considering future states or planning ahead. The robot acts based on what it “sees” right now.
- Inspiration – Think about Particles or Flocking:
- Particles: Imagine a collection of particles (e.g., in a fluid or gas) that move based on local interactions. If two particles get too close, they repel each other. This is similar to how a robot might avoid an obstacle it detects nearby.
- Flocking: Think of birds or fish moving in a group. Each individual adjusts its movement based on the position and velocity of its neighbors (e.g., avoid collisions, stay close). This behavior is modeled using rules like “maintain distance” or “align direction.”
- These ideas are often implemented using force-based methods (e.g., Potential Fields), where the robot reacts to repulsive forces from obstacles and attractive forces from the goal.
- How It Works:
- The robot uses real-time sensor inputs (e.g., LiDAR, cameras) to detect obstacles.
- It applies simple rules or algorithms to adjust its motion instantly (e.g., “if obstacle on right, turn left”).
- No memory of past states or prediction of future states is typically involved.
- Examples from Earlier:
- Potential Fields: The robot reacts to the net force from obstacles and the goal at each moment (Reynolds 1987, Helbing et al. 2000).
- Braitenberg Vehicles: A simple reactive rule-based system where the robot turns away from obstacles based on sensor readings.
Connection to Local Collision Avoidance
- Reactive methods are ideal for dynamic, unpredictable environments where the robot must respond quickly (e.g., a robot navigating a crowded room).
- Pros: Fast, computationally lightweight, works well with limited sensor data.
- Cons: Lacks foresight, so it can get stuck in local minima (e.g., oscillating between obstacles) or fail with moving obstacles.
Real-World Analogy
Think of a person dodging a ball thrown at them instinctively—they react to the ball’s current position without predicting its full trajectory.
2. Predictive
Explanation
- What It Is: Predictive methods involve the robot anticipating future states of the environment and planning its actions accordingly. The robot doesn’t just react to what it sees now—it tries to “think ahead.”
- Inspiration – Think about Human Behavior:
- Humans often predict others’ movements to avoid collisions. For example, when walking in a crowded street, you might step aside because you anticipate someone’s path, not just because they’re close.
- This behavior involves estimating trajectories, understanding intent (e.g., someone is heading toward you), and planning a safe response.
- Predictive methods often use velocity-based or control-based approaches, where the robot models the motion of itself and obstacles over time.
- How It Works:
- The robot uses sensor data to predict the future positions of itself and obstacles (e.g., using velocity vectors or motion models).
- It then plans a path or control sequence that avoids predicted collisions while moving toward the goal.
- Techniques like Model Predictive Control (MPC) or Velocity Obstacles (VO) are common, where the robot optimizes its actions over a short time horizon.
- Examples from Earlier:
- Velocity-Based (e.g., Dynamic Window Approach): The robot evaluates possible velocities based on predicted obstacle positions (Fox et al. 1997, van den Berg et al. 2011).
- Control-Based (e.g., Model Predictive Control): The robot plans a sequence of control inputs, predicting its trajectory to avoid obstacles (Wilkie et al. 2009, Davis et al. 2020).
Connection to Local Collision Avoidance
- Predictive methods shine in scenarios with moving obstacles (e.g., a self-driving car avoiding pedestrians) or when precise trajectories are needed (e.g., a drone flying through a narrow gap).
- Pros: Better handling of dynamic environments, smoother paths, and more robust to complex situations.
- Cons: Requires more computational power and accurate motion models, which can be challenging with noisy sensor data.
Real-World Analogy
Think of a soccer player anticipating where the ball will go based on the kicker’s movement and adjusting their position to intercept it.
Comparing Reactive vs. Predictive
| Category | Behavior | Inspiration | Strengths | Weaknesses |
|---|---|---|---|---|
| Reactive | Immediate response to sensors | Particles, flocking | Fast, simple, lightweight | No foresight, local minima |
| Predictive | Plans based on future states | Human behavior | Handles dynamics, precise | Computationally intensive |
Linking Behavior-Wise to Implementation-Wise
The previous slide categorized methods by implementation (Force-Based, Velocity-Based, Control-Based), while this slide focuses on behavior. Here’s how they align:
- Reactive:
- Often implemented with Force-Based methods (e.g., Potential Fields) to model instant repulsion/attraction.
- Can also use simple Velocity-Based rules (e.g., turn away from obstacles).
- Predictive:
- Typically relies on Velocity-Based methods (e.g., Velocity Obstacles, DWA) to predict motion.
- Often uses Control-Based methods (e.g., MPC) for detailed trajectory planning.
This shows that the behavior (reactive vs. predictive) influences the choice of implementation, depending on the robot’s needs and environment.
How to Learn This
- Explore Reactive Methods:
- Start with Potential Fields. Simulate a robot reacting to obstacles using Python (e.g., calculate forces and update position).
- Study flocking algorithms (e.g., Reynolds’ boids model) to see how local rules create group behavior.
- Explore Predictive Methods:
- Try Velocity Obstacles. Simulate a robot avoiding a moving obstacle by predicting its path.
- Experiment with MPC in a simulator like ROS Gazebo, planning control inputs over time.
- Hands-On Ideas:
- Code a reactive robot: Use sensor data to make it turn away from obstacles.
- Code a predictive robot: Add a simple prediction step (e.g., assume an obstacle moves straight) and plan accordingly.
- Resources:
- Read about flocking in Reynolds’ 1987 paper or Helbing’s 2000 pedestrian model.
- Look into DWA or MPC tutorials online (e.g., ROS documentation or robotics courses).
Let’s dive into the Forward Euler method, which was mentioned in the slide on the Reactive Force-Based Approach for local collision avoidance. The slide used Forward Euler integration to update the robot’s velocity and position based on forces, and now we’ll explore what this method is, why it’s used, and how it works in the context of robotics and beyond. I’ll break it down clearly, provide examples, and connect it to the collision avoidance process.
What is the Forward Euler Method?
The Forward Euler method (also called the Euler method) is a simple numerical technique used to approximate solutions to ordinary differential equations (ODEs). In robotics, physics simulations, and many other fields, ODEs describe how quantities (like position, velocity, or temperature) change over time. The Forward Euler method helps us compute these changes step-by-step when an exact solution isn’t feasible.
In essence, Forward Euler is a way to predict the future state of a system (e.g., a robot’s position) by assuming that the rate of change (e.g., velocity or acceleration) remains constant over a small time step $\Delta t$.
Why Use Forward Euler in Robotics?
In the context of the slide, the robot’s motion is governed by forces, which affect its velocity and position over time. These relationships are described by differential equations:
- Force leads to acceleration ($F = ma$), which changes velocity ($\frac{dv}{dt} = a$).
- Velocity changes position ($\frac{dx}{dt} = v$).
The Forward Euler method is used to approximate how the robot’s velocity $v$ and position $x$ evolve over time by breaking the continuous motion into discrete time steps. It’s popular because:
- Simplicity: It’s easy to understand and implement.
- Speed: It’s computationally lightweight, making it suitable for real-time applications like robotics.
- Good Enough for Small Steps: If the time step $\Delta t$ is small, the approximation is reasonably accurate for many systems.
How Does Forward Euler Work?
The Forward Euler method is based on the idea of a first-order Taylor approximation. For a differential equation of the form:
$$
\frac{dx}{dt} = f(x, t)
$$
where $x$ is the quantity we’re tracking (e.g., position or velocity), $t$ is time, and $f(x, t)$ is the rate of change of $x$, the Forward Euler method approximates the next value of $x$ as:
$$
x(t + \Delta t) \approx x(t) + \Delta t \cdot f(x, t)
$$
In other words:
- Start with the current value of $x$.
- Compute the rate of change $f(x, t)$ at the current time.
- Multiply the rate of change by a small time step $\Delta t$ to estimate how much $x$ changes.
- Add this change to the current $x$ to get the new value.
Forward Euler in the Slide
The slide applies Forward Euler to update the robot’s velocity and position based on forces. Let’s break down the equations:
$$
v += F \Delta t
$$
$$
x += v \Delta t
$$
Step 1: Update Velocity ($v += F \Delta t$)
- Differential Equation: The force $F$ acts on the robot, causing acceleration. Assuming the robot’s mass is 1 (for simplicity, so $F = ma$ becomes $F = a$), the acceleration is $a = F$. The rate of change of velocity is:$$
\frac{dv}{dt} = a = F
$$ - Forward Euler Approximation:
- The change in velocity over a small time step $\Delta t$ is:$$
\Delta v = F \Delta t
$$ - The new velocity is:$$
v_{\text{new}} = v_{\text{old}} + F \Delta t
$$ - In code, this is written as $v += F \Delta t$, meaning “add $F \Delta t$ to the current velocity.”
- The change in velocity over a small time step $\Delta t$ is:$$
Step 2: Update Position ($x += v \Delta t$)
- Differential Equation: The velocity $v$ determines how the position changes over time:$$
\frac{dx}{dt} = v
$$ - Forward Euler Approximation:
- The change in position over a small time step $\Delta t$ is:$$
\Delta x = v \Delta t
$$ - The new position is:$$
x_{\text{new}} = x_{\text{old}} + v \Delta t
$$ - In code, this is written as $x += v \Delta t$.
- The change in position over a small time step $\Delta t$ is:$$
Why Small $\Delta t$?
The slide emphasizes using a small $\Delta t$. This is because Forward Euler assumes the rate of change ($F$ for velocity, $v$ for position) is constant over the time step. If $\Delta t$ is too large, this assumption becomes inaccurate, leading to errors (e.g., the robot might overshoot its intended path).
Example: Applying Forward Euler to a Robot’s Motion
Let’s revisit the example from the previous response to see Forward Euler in action.
Setup (Same as Before)
- Robot Position: $x = (0, 0)$
- Velocity: $v = (0, 0)$
- Total Force: $F = (4.64, -0.18)$ (calculated from attractive and repulsive forces)
- Time Step: $\Delta t = 0.1$
Step 1: Update Velocity
- Differential equation: $\frac{dv}{dt} = F$
- Forward Euler:$$
v_{\text{new}} = v_{\text{old}} + F \Delta t
$$
$$
v = (0, 0) + (4.64, -0.18) \cdot 0.1 = (0.464, -0.018)
$$
Step 2: Update Position
- Differential equation: $\frac{dx}{dt} = v$
- Forward Euler:$$
x_{\text{new}} = x_{\text{old}} + v \Delta t
$$
$$
x = (0, 0) + (0.464, -0.018) \cdot 0.1 = (0.0464, -0.0018)
$$
This matches the result from the previous example. The robot moves slightly toward the goal while veering to avoid the obstacle, and Forward Euler ensures the motion is updated in small, discrete steps.
A More General Example: 1D Motion
Let’s try a simpler 1D example to illustrate Forward Euler outside the robotics context.
Problem
A particle moves in 1D with velocity $v$, and its velocity changes due to a constant acceleration $a = 2 \, \text{m/s}^2$. The position changes based on velocity. Initial conditions:
- Position: $x(0) = 0 \, \text{m}$
- Velocity: $v(0) = 0 \, \text{m/s}$
- Time step: $\Delta t = 0.1 \, \text{s}$
We want to compute the position and velocity after 0.2 seconds (two time steps).
Differential Equations
- $\frac{dv}{dt} = a = 2$
- $\frac{dx}{dt} = v$
Step 1: $t = 0$ to $t = 0.1$
- Velocity:$$
v(0.1) = v(0) + a \Delta t = 0 + 2 \cdot 0.1 = 0.2 \, \text{m/s}
$$ - Position:$$
x(0.1) = x(0) + v(0) \Delta t = 0 + 0 \cdot 0.1 = 0 \, \text{m}
$$
Step 2: $t = 0.1$ to $t = 0.2$
- Velocity:$$
v(0.2) = v(0.1) + a \Delta t = 0.2 + 2 \cdot 0.1 = 0.4 \, \text{m/s}
$$ - Position:$$
x(0.2) = x(0.1) + v(0.1) \Delta t = 0 + 0.2 \cdot 0.1 = 0.02 \, \text{m}
$$
Exact Solution (for Comparison)
The exact solution to these equations ($\frac{dv}{dt} = 2$, $\frac{dx}{dt} = v$) is:
- $v(t) = 2t$
- $x(t) = t^2$
At $t = 0.2$: - $v(0.2) = 2 \cdot 0.2 = 0.4 \, \text{m/s}$ (matches Forward Euler)
- $x(0.2) = (0.2)^2 = 0.04 \, \text{m}$ (Forward Euler gives 0.02, so there’s some error)
The error in position occurs because Forward Euler uses the velocity at the start of each time step, not the average velocity over the interval. A smaller $\Delta t$ would reduce this error.
Strengths and Weaknesses of Forward Euler
Strengths
- Simple: Easy to implement in code.
- Fast: Requires minimal computation, ideal for real-time systems like robotics.
- Intuitive: Directly approximates the physics of motion (force → velocity → position).
Weaknesses
- Accuracy: Forward Euler is a first-order method, meaning its error is proportional to $\Delta t$. Larger time steps lead to bigger errors.
- Stability: If $\Delta t$ is too large, the method can become unstable (e.g., the robot’s position might oscillate wildly).
- Not Predictive: It only uses the current rate of change, not future trends, which can be a limitation for systems with rapid changes.
Alternatives
For more accuracy, you might use:
- Runge-Kutta Methods (e.g., RK4): Higher-order methods that take multiple samples of the rate of change within each time step.
- Implicit Euler: Uses the rate of change at the end of the time step (more stable but harder to compute).
These methods are more accurate but also more computationally expensive, which is why Forward Euler is often preferred in real-time robotics applications like collision avoidance.
How to Use Forward Euler in Robotics
In the context of local collision avoidance:
- Model the System: Define the differential equations (e.g., $\frac{dv}{dt} = F$, $\frac{dx}{dt} = v$).
- Choose a Time Step: Pick a small $\Delta t$ (e.g., 0.01 seconds) to ensure accuracy.
- Update in a Loop:
- Compute the forces $F$ based on sensor data.
- Use Forward Euler to update velocity and position.
- Repeat at each time step.
Python Code Example
Here’s a simple Python script to simulate the robot’s motion using Forward Euler:
import numpy as np
import matplotlib.pyplot as plt
# Parameters
dt = 0.1 # Time step
num_steps = 100 # Number of steps
k_att = 1.0 # Attractive force gain
k_rep = 2.0 # Repulsive force gain
# Initial conditions
x = np.array([0.0, 0.0]) # Robot position
v = np.array([0.0, 0.0]) # Robot velocity
goal = np.array([5.0, 0.0]) # Goal position
obstacle = np.array([2.0, 1.0]) # Obstacle position
# Store positions for plotting
positions = [x.copy()]
# Simulation loop
for _ in range(num_steps):
# Attractive force to goal
F_att = k_att * (goal - x)
# Repulsive force from obstacle
diff = x - obstacle
dist = np.linalg.norm(diff)
if dist > 0: # Avoid division by zero
F_rep = k_rep * (1 / dist**2) * (diff / dist)
else:
F_rep = np.array([0.0, 0.0])
# Total force
F = F_att + F_rep
# Forward Euler: Update velocity and position
v += F * dt
x += v * dt
# Store position
positions.append(x.copy())
# Plot the trajectory
positions = np.array(positions)
plt.plot(positions[:, 0], positions[:, 1], label="Robot Path")
plt.plot(goal[0], goal[1], "go", label="Goal")
plt.plot(obstacle[0], obstacle[1], "ro", label="Obstacle")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
plt.grid()
plt.show()
This code simulates a robot moving toward a goal while avoiding an obstacle, using Forward Euler to update its motion. You can run it to visualize the path.
Reactive force-base approach

Let’s break down the slide on the Reactive Force-Based Approach for local collision avoidance in robotics. This slide provides a step-by-step explanation of how a robot (referred to as an “agent”) uses a force-based method to navigate reactively, specifically focusing on the Artificial Potential Fields (APF) technique. It describes the process of sensing, calculating forces, and updating the robot’s motion using Forward Euler integration. I’ll explain each part in detail, connect it to what we’ve discussed previously, and provide a simple example to illustrate the concept.
Overview of the Slide
The slide outlines how a robot implements a reactive force-based approach (like Potential Fields) to avoid obstacles. It describes a cyclic process where the robot senses its environment, calculates forces, updates its velocity and position, and repeats this process in small time steps. This aligns with the Reactive behavior category from the earlier slide (behavior-wise classification) and the Force-Based method from the implementation-wise classification.
Detailed Explanation of Each Point
1. Agent Performs a Continuous Cycle of Sensing and Acting with Time Step Δt
- What It Means:
- The robot operates in a loop: at every time step $\Delta t$ (a small time interval, e.g., 0.01 seconds), it senses its environment and decides how to act.
- Sensing: The robot uses sensors (e.g., LiDAR, ultrasonic sensors) to detect obstacles and the goal.
- Acting: The robot adjusts its movement based on the sensed data.
- Why a Small Time Step $\Delta t$:
- A small $\Delta t$ ensures the robot reacts quickly to changes in the environment (e.g., a moving obstacle). It also makes the motion updates smooth and prevents large, jerky movements.
- Connection to Reactivity:
- This cyclic process is inherently reactive because the robot only considers the current state of the environment (what it senses now) and does not predict future states.
2. In Each Cycle, Let $F$ Denote All the Forces Exerted on the Agent
- What It Means:
- At each time step, the robot calculates the total force $F$ acting on it. This force is the sum of:
- Attractive Force ($F_{\text{att}}$): Pulls the robot toward the goal.
- Repulsive Force ($F_{\text{rep}}$): Pushes the robot away from obstacles.
- So, $F = F_{\text{att}} + F_{\text{rep}}$.
- At each time step, the robot calculates the total force $F$ acting on it. This force is the sum of:
- How Forces Are Calculated:
- Attractive Force: Typically proportional to the distance to the goal. For example:$$
F_{\text{att}} = k_{\text{att}} \cdot (x_{\text{goal}} – x_{\text{agent}})
$$
where $k_{\text{att}}$ is a gain constant, $x_{\text{goal}}$ is the goal position, and $x_{\text{agent}}$ is the robot’s position. - Repulsive Force: Usually inversely proportional to the distance to the obstacle (stronger when closer). For example:$$
F_{\text{rep}} = k_{\text{rep}} \cdot \frac{1}{d^2} \cdot \text{(direction away from obstacle)}
$$
where $k_{\text{rep}}$ is a gain constant, $d$ is the distance to the obstacle, and the direction is away from the obstacle.
- Attractive Force: Typically proportional to the distance to the goal. For example:$$
- Connection to Potential Fields:
- This is the core of the Artificial Potential Fields (APF) method we discussed earlier. The forces are derived from a potential field, where the goal is a “low potential” (attractive) and obstacles are “high potential” (repulsive).
3. Then, We Can Use Simple Forward Euler Integration to Compute a New Velocity for the Agent (Use a Small $\Delta t$)
- Equations:$$
v += F \Delta t
$$
$$
x += v \Delta t
$$ - What It Means:
- The robot updates its velocity ($v$) and position ($x$) at each time step using the total force $F$.
- This is done using Forward Euler integration, a numerical method to approximate the motion of the robot over time.
- Step 1: Update Velocity ($v += F \Delta t$):
- The force $F$ acts like an acceleration (assuming the robot’s mass is 1 for simplicity, so $F = ma$ becomes $F = a$).
- The change in velocity is the force multiplied by the time step: $\Delta v = F \Delta t$.
- The new velocity is:$$
v_{\text{new}} = v_{\text{old}} + F \Delta t
$$ - This assumes the force $F$ is in units that match the velocity (e.g., $F$ might be scaled appropriately).
- Step 2: Update Position ($x += v \Delta t$):
- The robot’s position changes based on its velocity over the time step: $\Delta x = v \Delta t$.
- The new position is:$$
x_{\text{new}} = x_{\text{old}} + v \Delta t
$$ - Here, $x$ and $v$ are typically vectors (e.g., in 2D, $x = (x, y)$, $v = (v_x, v_y)$).
- Why Forward Euler?:
- Forward Euler is a simple way to approximate the motion of the robot. It assumes the force and velocity are constant over the small time step $\Delta t$.
- A small $\Delta t$ ensures accuracy—if $\Delta t$ is too large, the approximation becomes inaccurate, and the robot’s motion may look unnatural or overshoot.
Putting It All Together: How the Process Works
Here’s the full cycle at each time step $\Delta t$:
- Sense: The robot uses sensors to detect the goal and obstacles.
- Calculate Forces:
- Compute the attractive force toward the goal.
- Compute the repulsive forces from all nearby obstacles.
- Sum them to get the total force $F$.
- Update Velocity: Use $v += F \Delta t$ to adjust the robot’s velocity based on the force.
- Update Position: Use $x += v \Delta t$ to move the robot to a new position.
- Repeat: Go back to step 1 for the next time step.
This process makes the robot react to its environment in real-time, adjusting its path to avoid obstacles while moving toward the goal.
Simple Example
Let’s walk through a 2D example to see how this works.
Setup
- Robot Position: $x = (0, 0)$
- Goal Position: $x_{\text{goal}} = (5, 0)$
- Obstacle Position: $x_{\text{obs}} = (2, 1)$
- Initial Velocity: $v = (0, 0)$
- Time Step: $\Delta t = 0.1$
- Force Constants:
- Attractive gain: $k_{\text{att}} = 1$
- Repulsive gain: $k_{\text{rep}} = 2$
Step 1: Calculate Forces
- Attractive Force:
- Direction to goal: $(5, 0) – (0, 0) = (5, 0)$
- Magnitude: $F_{\text{att}} = k_{\text{att}} \cdot (5, 0) = (5, 0)$
- Repulsive Force:
- Direction to obstacle: $(2, 1) – (0, 0) = (2, 1)$
- Distance to obstacle: $d = \sqrt{(2)^2 + (1)^2} = \sqrt{5} \approx 2.24$
- Repulsive force magnitude: $\frac{k_{\text{rep}}}{d^2} = \frac{2}{(2.24)^2} \approx 0.4$
- Direction away from obstacle: $(0, 0) – (2, 1) = (-2, -1)$, normalized to $\left(-\frac{2}{\sqrt{5}}, -\frac{1}{\sqrt{5}}\right)$
- $F_{\text{rep}} = 0.4 \cdot \left(-\frac{2}{\sqrt{5}}, -\frac{1}{\sqrt{5}}\right) \approx (-0.36, -0.18)$
- Total Force:
- $F = F_{\text{att}} + F_{\text{rep}} = (5, 0) + (-0.36, -0.18) \approx (4.64, -0.18)$
Step 2: Update Velocity
- Initial velocity: $v = (0, 0)$
- $v += F \Delta t = (0, 0) + (4.64, -0.18) \cdot 0.1 = (0.464, -0.018)$
Step 3: Update Position
- Initial position: $x = (0, 0)$
- $x += v \Delta t = (0, 0) + (0.464, -0.018) \cdot 0.1 = (0.0464, -0.0018)$
Result After One Step
- New velocity: $v = (0.464, -0.018)$
- New position: $x = (0.0464, -0.0018)$
The robot moves slightly toward the goal (mostly in the x-direction) but also slightly downward to avoid the obstacle. In the next cycle, it repeats the process with the new position.
How to Learn This Hands-On
- Code a Simulation:
- Use Python with libraries like
numpyfor vector math andmatplotlibto visualize the robot’s path. - Write a loop that:
- Calculates attractive and repulsive forces.
- Updates velocity and position using Forward Euler.
- Plots the robot’s trajectory.
- Use Python with libraries like
- Experiment:
- Add multiple obstacles and see how the robot reacts.
- Adjust $\Delta t$, $k_{\text{att}}$, and $k_{\text{rep}}$ to observe their effects (e.g., a larger $\Delta t$ might cause overshooting).
- Simulate in ROS:
- Use ROS and Gazebo to simulate a real robot (e.g., TurtleBot) with this method. The ROS navigation stack supports potential fields as a local planner.
Let’s dive into the slides on the Reactive Force-Based Approach, focusing on the two key components presented: the Driving Force (from the first slide) and the Avoidance Forces (from the subsequent slides). These slides build on the earlier concepts of reactive navigation using forces (e.g., Artificial Potential Fields) and provide specific formulas for how an agent (robot) adjusts its motion toward a goal and away from obstacles. I’ll explain each part step-by-step, connect them to the broader context, and include examples to solidify your understanding.

Overview
The reactive force-based approach models the robot’s movement as a response to forces calculated at each time step $\Delta t$. These forces guide the robot toward its goal (driving force) and away from obstacles or other agents (avoidance forces). This aligns with the Force-Based implementation and Reactive behavior we discussed earlier, using Forward Euler integration to update the robot’s motion.
1. Driving Force
Explanation
- Concept: The driving force $F_{\text{goal}}$ is the force that pushes the robot toward its goal. It’s designed to adjust the robot’s current velocity $v$ to the desired goal velocity $v_g$ over time.
- Assumption: The slide assumes the agent adapts its current velocity to the goal velocity within a “characteristic” time $\tau$. This $\tau$ represents how quickly the robot should align its motion with the goal—think of it as a damping or adjustment time constant.
- Formula:$$
F_{\text{goal}} = \frac{v_g – v}{\tau}
$$- $v_g$: The desired velocity toward the goal (e.g., a vector pointing from the robot’s current position to the goal, normalized and scaled by a desired speed).
- $v$: The robot’s current velocity.
- $\tau$: The characteristic time (a positive constant, e.g., 0.5 seconds), which controls the rate of adaptation.
- The difference $v_g – v$ is the velocity error (how far the current velocity is from the goal velocity), and dividing by $\tau$ scales this error into a force.
- Intuition:
- If the robot’s current velocity $v$ is much slower than $v_g$ (e.g., it’s stationary and the goal is ahead), $F_{\text{goal}}$ will be large and positive, accelerating the robot toward the goal.
- If $v$ is close to $v_g$, the force is small, allowing the robot to maintain its course smoothly.
- The $\tau$ acts like a “relaxation time”—a smaller $\tau$ means faster adjustment, while a larger $\tau$ means slower, smoother changes.
- Connection to Potential Fields:
- This driving force is a form of the attractive force in Potential Fields, but it’s expressed in terms of velocity adjustment rather than a direct position-based attraction. It ensures the robot moves toward the goal without overshooting, thanks to the damping effect of $\tau$.
Example
- Setup:
- Robot position: $x = (0, 0)$
- Goal position: $x_{\text{goal}} = (5, 0)$
- Desired goal velocity: $v_g = (1, 0)$ m/s (e.g., 1 m/s toward the goal)
- Current velocity: $v = (0, 0)$ m/s
- Characteristic time: $\tau = 0.5$ s
- Calculation:$$
F_{\text{goal}} = \frac{v_g – v}{\tau} = \frac{(1, 0) – (0, 0)}{0.5} = \frac{(1, 0)}{0.5} = (2, 0) \, \text{(force units)}
$$ - Result: The robot experiences a force of $(2, 0)$, which, when integrated with Forward Euler ($v += F_{\text{goal}} \Delta t$), will increase its velocity toward the goal. After a time step $\Delta t = 0.1$ s:$$
v_{\text{new}} = (0, 0) + (2, 0) \cdot 0.1 = (0.2, 0) \, \text{m/s}
$$
2. Avoidance Forces
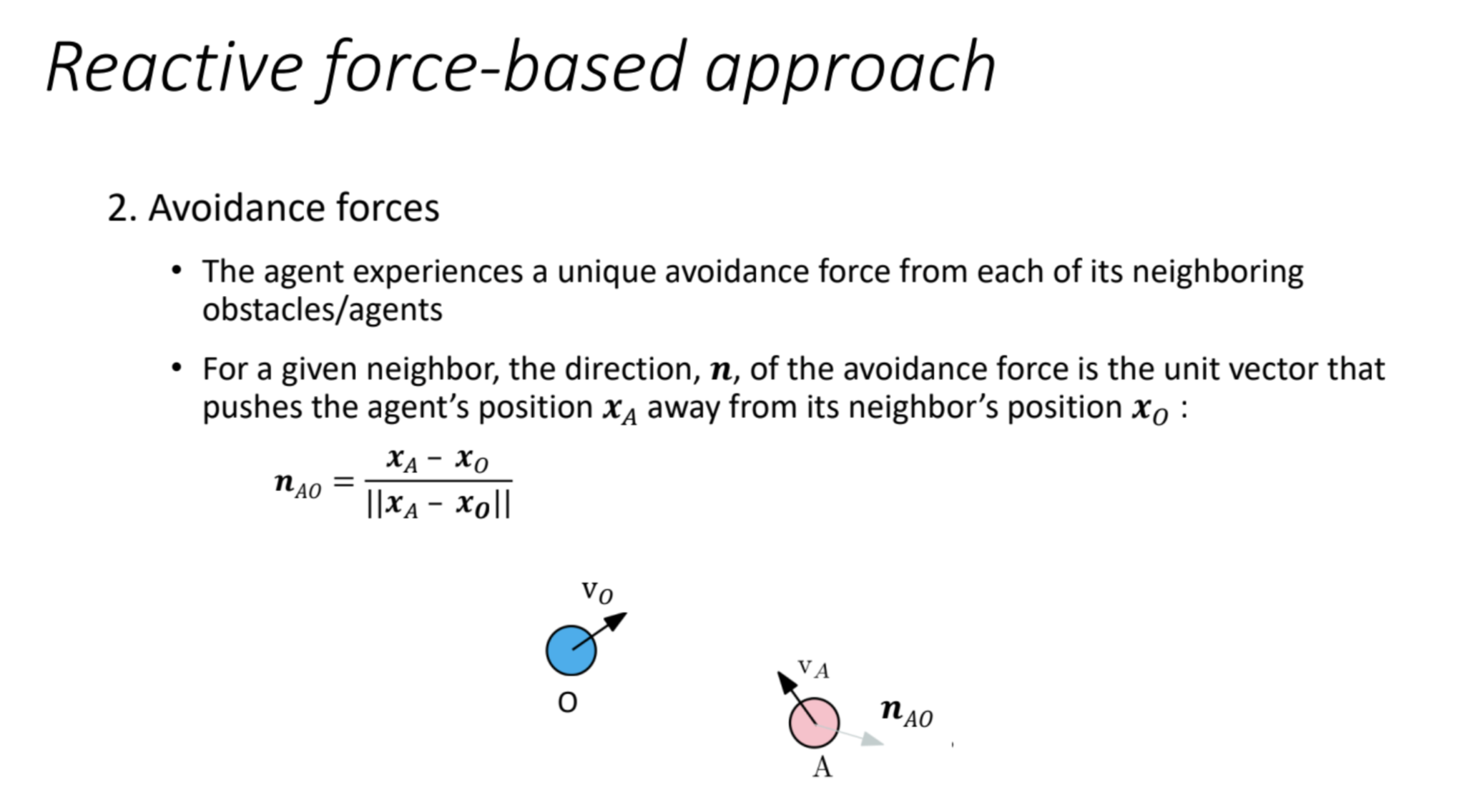
Explanation
The avoidance forces ensure the robot avoids collisions with neighboring obstacles or other agents. Let’s break down the two slides:
Direction of Avoidance Force
- Concept: Each obstacle or agent exerts a unique avoidance force on the robot, pushing it away to prevent collisions.
- Direction ($n_{AO}$):
- $n_{AO}$ is the unit vector that defines the direction of the avoidance force.
- It points from the neighbor’s position $x_O$ (obstacle/agent) to the robot’s position $x_A$, ensuring the robot moves away.
- Formula:$$
n_{AO} = \frac{x_A – x_O}{\|x_A – x_O\|}
$$- $x_A$: Robot’s position (agent A).
- $x_O$: Neighbor’s position (obstacle O).
- $\|x_A – x_O\|$: The Euclidean distance between the robot and the neighbor, used to normalize the vector into a unit vector (magnitude 1).
- This direction is the opposite of the vector from the robot to the obstacle ($x_O – x_A$), ensuring repulsion.
- Diagram:
- The blue circle (O) is the obstacle, and the pink circle (A) is the robot.
- $v_O$ and $v_A$ are their velocities, but the key is $n_{AO}$, the unit vector pushing A away from O.
- Intuition:
- The force direction always points away from the obstacle, regardless of the robot’s or obstacle’s velocity. This is a reactive response based on current positions.
Example
- Setup:
- Robot position: $x_A = (2, 1)$
- Obstacle position: $x_O = (0, 0)$
- Distance: $\|x_A – x_O\| = \sqrt{(2-0)^2 + (1-0)^2} = \sqrt{5} \approx 2.24$
- Calculation:$$
x_A – x_O = (2, 1) – (0, 0) = (2, 1)
$$
$$
n_{AO} = \frac{(2, 1)}{\sqrt{5}} \approx \left(\frac{2}{2.24}, \frac{1}{2.24}\right) \approx (0.894, 0.447)
$$ - Result: The unit vector $n_{AO} \approx (0.894, 0.447)$ points from the obstacle to the robot, and the avoidance force will be in this direction (or its negative, depending on the force definition).
Magnitude of Avoidance Force

- Concept: The magnitude of the avoidance force depends on the distance between the robot and the obstacle, with stronger repulsion when closer.
- Distance $d_{AO}$:
- Defined as:$$
d_{AO} = \|x_A – x_O\| – r_A – r_O
$$- $\|x_A – x_O\|$: Distance between the robot and obstacle.
- $r_A$: Radius of the robot (its size).
- $r_O$: Radius of the obstacle.
- This adjusts the distance to account for the physical sizes of both objects, ensuring avoidance starts before they touch.
- Defined as:$$
- Force Magnitude:
- Formula:$$
F_{\text{avoid}} = \frac{k}{d_{AO}} n_{AO}
$$- $k$: A scaling constant that controls the strength of the repulsion.
- $d_{AO}$: The effective distance (must be positive; if $d_{AO} \leq 0$, the robot is inside the obstacle, and the force might be set to a maximum or handled separately).
- $n_{AO}$: The unit vector from the obstacle to the robot.
- Formula:$$
- Intuition:
- The force is inversely proportional to $d_{AO}$, so it increases as the robot gets closer to the obstacle (e.g., $1/d$ behavior, similar to gravitational or electrostatic repulsion).
- The $k$ constant allows tuning—e.g., a larger $k$ makes the robot more cautious.
- Diagram:
- $d_{AO}$ is the effective distance, and $F_{\text{avoid}}$ is the resulting force vector, aligned with $n_{AO}$.
Example
- Setup (Continuing from Above):
- $x_A = (2, 1)$, $x_O = (0, 0)$
- $\|x_A – x_O\| = \sqrt{5} \approx 2.24$
- Robot radius: $r_A = 0.5$ m
- Obstacle radius: $r_O = 0.5$ m
- Scaling constant: $k = 1$
- Calculation:$$
d_{AO} = 2.24 – 0.5 – 0.5 = 1.24 \, \text{m}
$$
$$
F_{\text{avoid}} = \frac{k}{d_{AO}} n_{AO} = \frac{1}{1.24} \cdot (0.894, 0.447) \approx (0.721, 0.360)
$$ - Result: The avoidance force is approximately $(0.721, 0.360)$, pushing the robot away from the obstacle. This force would be added to the driving force and integrated with Forward Euler.
Putting It All Together
The total force on the robot at each $\Delta t$ is:
$$
F_{\text{total}} = F_{\text{goal}} + \sum F_{\text{avoid}}
$$
- $F_{\text{goal}} = \frac{v_g – v}{\tau}$ drives the robot toward the goal.
- $\sum F_{\text{avoid}}$ is the sum of avoidance forces from all nearby obstacles/agents, each calculated as $\frac{k}{d_{AO}} n_{AO}$.
This total force is then used with Forward Euler ($v += F_{\text{total}} \Delta t$, $x += v \Delta t$) to update the robot’s motion.
Full Example
- Setup:
- $x_A = (0, 0)$, $v = (0, 0)$
- $x_{\text{goal}} = (5, 0)$, $v_g = (1, 0)$, $\tau = 0.5$
- $x_O = (2, 1)$, $r_A = 0.5$, $r_O = 0.5$, $k = 1$
- $\Delta t = 0.1$
- Driving Force:$$
F_{\text{goal}} = \frac{(1, 0) – (0, 0)}{0.5} = (2, 0)
$$ - Avoidance Force:
- $d_{AO} = \sqrt{5} – 0.5 – 0.5 = 1.24$
- $n_{AO} \approx (0.894, 0.447)$
- $F_{\text{avoid}} \approx \frac{1}{1.24} \cdot (0.894, 0.447) \approx (0.721, 0.360)$
- Total Force:$$
F_{\text{total}} = (2, 0) + (0.721, 0.360) \approx (2.721, 0.360)
$$ - Update:$$
v_{\text{new}} = (0, 0) + (2.721, 0.360) \cdot 0.1 = (0.2721, 0.0360)
$$
$$
x_{\text{new}} = (0, 0) + (0.2721, 0.0360) \cdot 0.1 = (0.02721, 0.00360)
$$
The robot moves toward the goal while slightly adjusting to avoid the obstacle.
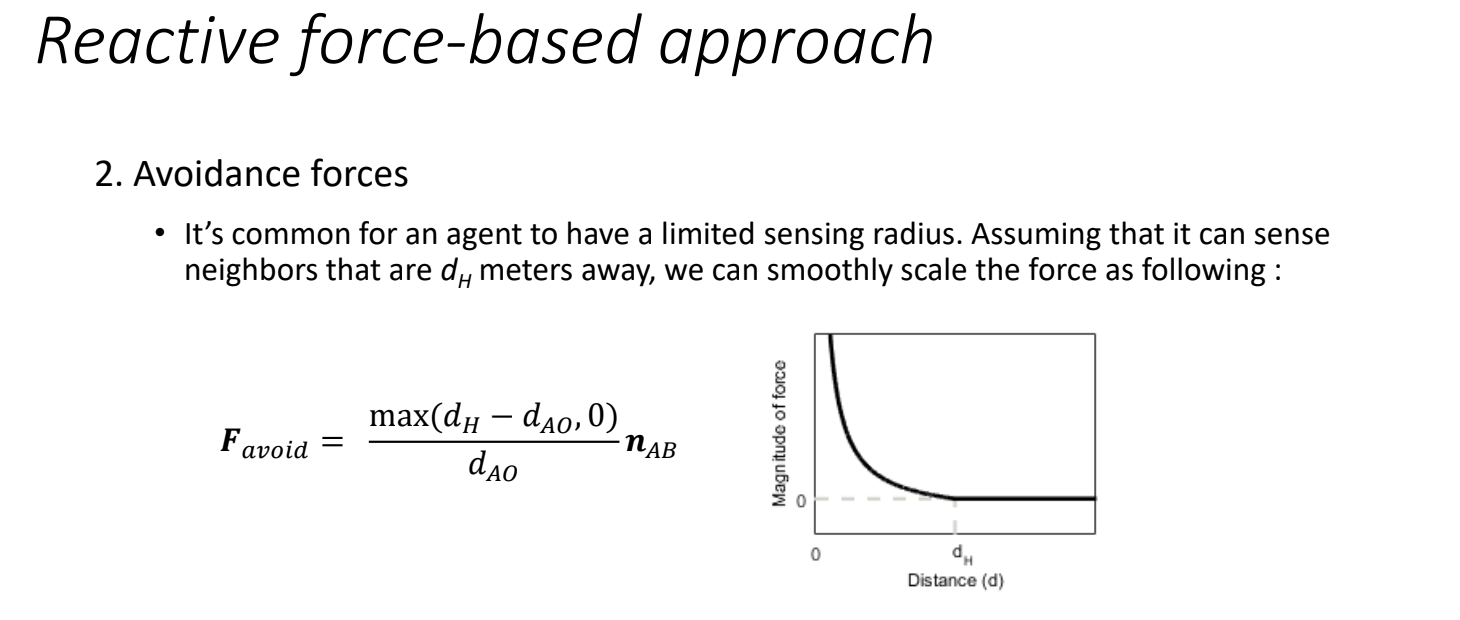
Overview
The slide continues the discussion of how a robot (agent) uses reactive forces to avoid obstacles or other agents. The key innovation here is the consideration of a limited sensing radius and a smooth scaling function for the avoidance force, which makes the robot’s behavior more natural and computationally manageable.
Detailed Explanation
Key Points
- Limited Sensing Radius:
- It’s common for a robot to have a finite sensing range, denoted as $d_H$ (the maximum distance at which it can detect neighbors, such as obstacles or other agents).
- Beyond $d_H$, the robot doesn’t sense or react to neighbors, which is realistic given sensor limitations (e.g., LiDAR or camera range).
- This assumption simplifies the computation by ignoring distant objects that pose no immediate threat.
- Smooth Scaling of Force:
- The avoidance force isn’t a simple inverse function (like $1/d$) but is scaled smoothly based on the distance $d_{AO}$ between the robot and the neighbor.
- The formula and graph suggest a function that peaks at close distances and diminishes as the distance approaches the sensing radius $d_H$.
- Formula:$$
F_{\text{avoid}} = \frac{\max(d_H – d_{AO}, 0)}{d_{AO}} n_{AB}
$$- Components:
- $d_H$: The sensing radius (maximum detection distance).
- $d_{AO}$: The effective distance between the agent (A) and the obstacle/agent (O), typically $\|x_A – x_O\| – r_A – r_O$ (distance minus radii, as seen in the previous slide).
- $\max(d_H – d_{AO}, 0)$: This ensures the force is zero if $d_{AO} > d_H$ (beyond sensing range) and positive otherwise. It represents the “remaining distance” within the sensing range.
- $d_{AO}$: Normalizes the force, preventing it from becoming infinite as $d_{AO}$ approaches zero (a limitation of the $1/d$ model).
- $n_{AB}$: The unit vector pointing away from the neighbor (similar to $n_{AO} = \frac{x_A – x_O}{\|x_A – x_O\|}$, though the slide uses $n_{AB}$, likely a typo or alternative notation for the same concept).
- Components:
- Graph:
- X-Axis (Distance $d$): Represents $d_{AO}$, the distance from the robot to the neighbor.
- Y-Axis (Magnitude of Force): Represents the magnitude of $F_{\text{avoid}}$.
- Shape: The curve starts at a high value when $d_{AO}$ is small (close proximity), decreases smoothly as $d_{AO}$ increases, and drops to zero at $d_{AO} = d_H$ (beyond the sensing radius).
- The dashed line at $y = 0$ indicates the force is zero outside the sensing range.
- Intuition:
- When the robot is very close to an obstacle ($d_{AO}$ small), the force is strong to ensure quick avoidance.
- As the distance increases, the force weakens, reflecting that the threat is less immediate.
- At $d_{AO} = d_H$, the force becomes zero, as the obstacle is no longer within the robot’s sensing range.
- The $\max$ function ensures a smooth transition, avoiding abrupt changes (e.g., a sudden drop to zero).
Mathematical Breakdown
Let’s dissect the formula $F_{\text{avoid}} = \frac{\max(d_H – d_{AO}, 0)}{d_{AO}} n_{AB}$:
- Numerator $\max(d_H – d_{AO}, 0)$:
- If $d_{AO} < d_H$, then $d_H – d_{AO} > 0$, and the force is proportional to the difference.
- If $d_{AO} \geq d_H$, then $d_H – d_{AO} \leq 0$, so $\max(d_H – d_{AO}, 0) = 0$, and the force is zero.
- Denominator $d_{AO}$:
- Prevents the force from becoming infinite as $d_{AO}$ approaches zero (unlike $1/d_{AO}$ alone, which would diverge).
- The ratio $\frac{d_H – d_{AO}}{d_{AO}}$ creates a hyperbolic-like decay, modified by the $\max$ function.
- Direction $n_{AB}$:
- Ensures the force pushes the robot away from the neighbor, consistent with previous slides ($n_{AO} = \frac{x_A – x_O}{\|x_A – x_O\|}$).
- Behavior:
- At $d_{AO} = 0$ (collision), the force magnitude would be $\frac{d_H}{0}$, which is undefined. In practice, a minimum distance or cap is often applied.
- At $d_{AO} = d_H$, the force is $\frac{0}{d_H} = 0$.
- At $d_{AO} = d_H / 2$, the force is $\frac{d_H – d_H / 2}{d_H / 2} = \frac{d_H / 2}{d_H / 2} = 1$ (scaled by $n_{AB}$), showing a moderate repulsion.
Example
Let’s compute the avoidance force for a specific case.
- Setup:
- Sensing radius: $d_H = 2$ m
- Robot position: $x_A = (2, 1)$
- Obstacle position: $x_O = (0, 0)$
- Robot radius: $r_A = 0.5$ m
- Obstacle radius: $r_O = 0.5$ m
- Distance: $\|x_A – x_O\| = \sqrt{5} \approx 2.24$ m
- Effective distance: $d_{AO} = 2.24 – 0.5 – 0.5 = 1.24$ m
- Unit vector: $n_{AO} = \frac{(2, 1)}{\sqrt{5}} \approx (0.894, 0.447)$ (assuming $n_{AB} = n_{AO}$)
- Calculation:
- Since $d_{AO} = 1.24 < d_H = 2$:$$
\max(d_H – d_{AO}, 0) = 2 – 1.24 = 0.76
$$
$$
F_{\text{avoid}} = \frac{0.76}{1.24} n_{AO} \approx \frac{0.76}{1.24} \cdot (0.894, 0.447) \approx (0.548, 0.274)
$$
- Since $d_{AO} = 1.24 < d_H = 2$:$$
- Result: The avoidance force is approximately $(0.548, 0.274)$, pushing the robot away from the obstacle. If $d_{AO}$ increased to 2.5 m (beyond $d_H$), the force would be zero.
Connection to Previous Slides
- Driving Force: The driving force ($F_{\text{goal}} = \frac{v_g – v}{\tau}$) pulls the robot toward the goal, while the avoidance force counteracts it to prevent collisions.
- Previous Avoidance Force: The earlier $F_{\text{avoid}} = \frac{k}{d_{AO}} n_{AO}$ had no sensing radius limit and could grow unbounded as $d_{AO}$ approached zero. This new formula adds a cap and smooth scaling.
- Forward Euler: This $F_{\text{avoid}}$ would be added to $F_{\text{goal}}$ and integrated with $v += F_{\text{total}} \Delta t$, $x += v \Delta t$.
Advantages of This Approach
- Realism: Limited sensing radius mimics real sensor constraints (e.g., LiDAR range).
- Smoothness: The $\max$ function avoids abrupt force changes, making the robot’s motion more stable.
- Efficiency: Ignores distant neighbors, reducing computational load.
Limitations
- Zero Force at $d_H$: The force drops to zero at the sensing boundary, which might allow the robot to get too close to the edge of its range.
- Singularity at $d_{AO} = 0$: Requires a minimum distance or cap to handle collisions.
- Tuning: $d_H$ and the scaling need careful adjustment for different environments.
How to Learn and Apply
- Code It:
- Modify the Python script from earlier to use $F_{\text{avoid}} = \frac{\max(d_H – d_{AO}, 0)}{d_{AO}} n_{AB}$.
- Example:
d_H = 2.0 d_AO = np.linalg.norm(x_A - x_O) - r_A - r_O if d_AO > 0 and d_AO < d_H: F_avoid = (max(d_H - d_AO, 0) / d_AO) * n_AO else: F_avoid = np.array([0.0, 0.0])
- Experiment:
- Vary $d_H$ (e.g., 1 m, 3 m) to see how the sensing radius affects avoidance.
- Test different $d_{AO}$ values to observe the force scaling.
- Simulate:
- Use ROS/Gazebo to test this with a robot model, adjusting the sensing radius based on sensor specs.
Let’s dive into the slide on Artificial Potential Fields, which provides a foundational concept for the reactive force-based approach to local collision avoidance in robotics that we’ve been exploring. This sidebar serves as a theoretical overview, explaining how a robot navigates using a potential energy function and its gradient. I’ll break down each point, interpret the diagram, and connect it to our previous discussions, offering examples to solidify your understanding.

Overview
Artificial Potential Fields (APF) is a widely used method in robotics for local navigation. It models the robot’s environment as a field of potential energy, where the robot is guided by forces derived from this potential. The robot moves toward a goal by following the negative gradient of the potential function, which represents the direction of steepest descent in energy. This approach aligns with the Force-Based reactive methods we’ve discussed, such as the driving and avoidance forces.
Detailed Explanation of Each Point
1. Let a robot be a point on the 2D Euclidean space located at $x$ having a goal $x_g$
- What It Means:
- The robot is treated as a point mass (a simplified model ignoring its physical size) moving in a 2D plane, represented by its position $x = (x_1, x_2)$.
- The goal is another point in this 2D space, denoted $x_g = (x_{g1}, x_{g2})$, which the robot aims to reach.
- Context:
- This abstraction simplifies calculations, assuming the robot’s motion is determined by its position relative to the goal and obstacles.
- In practice, the robot’s size and sensor data (e.g., from LiDAR) are considered, but the core idea starts with point-based navigation.
2. Let a potential function be defined as $U : \mathbb{R}^m \rightarrow \mathbb{R}$
- What It Means:
- A potential function $U$ maps points in an $m$-dimensional space ($\mathbb{R}^m$) to a scalar value (real number, $\mathbb{R}$).
- Here, $m = 2$ for 2D space, so $U : \mathbb{R}^2 \rightarrow \mathbb{R}$ defines the potential energy at any point $x$ in the plane.
- Purpose:
- $U(x)$ represents the “energy landscape” the robot navigates. Low energy states correspond to desirable positions (e.g., the goal), while high energy states correspond to undesirable ones (e.g., obstacles).
- The function is designed to have a minimum at the goal $x_g$ and peaks near obstacles.
- Example Potential Function:
- A common form combines an attractive potential (toward the goal) and a repulsive potential (from obstacles):
- Attractive Potential: $U_{\text{att}}(x) = \frac{1}{2} k_{\text{att}} \|x – x_g\|^2$, where $k_{\text{att}}$ is a gain constant, and $\|x – x_g\|$ is the Euclidean distance to the goal.
- Repulsive Potential: $$U_{\text{rep}}(x) = \begin{cases}
\frac{1}{2} k_{\text{rep}} \left(\frac{1}{|x – x_o|} – \frac{1}{d_0}\right)^2 & \text{if } |x – x_o| < d_0 \
0 & \text{otherwise}
\end{cases}$$, where $x_o$ is an obstacle’s position, $k_{\text{rep}}$ is a gain, and $d_0$ is a influence distance. - Total potential: $U(x) = U_{\text{att}}(x) + \sum U_{\text{rep}}(x)$.
- A common form combines an attractive potential (toward the goal) and a repulsive potential (from obstacles):
3. The robot seeks to move to a lower energy state by following the negative gradient of the potential energy function
- What It Means:
- The gradient of $U$, denoted $\nabla U$, is a vector that points in the direction of the steepest increase in potential energy.
- The negative gradient $-\nabla U$ points in the direction of the steepest decrease, guiding the robot toward a lower energy state (i.e., the goal or away from obstacles).
- The force acting on the robot is proportional to $-\nabla U$, as force is the negative gradient of potential energy in physics ($F = -\nabla U$).

- How It Works:
- At each point $x$, the robot calculates $\nabla U$ and moves in the direction of $-\nabla U$.
- For the attractive potential $U_{\text{att}} = \frac{1}{2} k_{\text{att}} \|x – x_g\|^2$:
- $\nabla U_{\text{att}} = k_{\text{att}} (x – x_g)$
- $F_{\text{att}} = -\nabla U_{\text{att}} = -k_{\text{att}} (x – x_g)$, pulling the robot toward $x_g$.
- For the repulsive potential (near an obstacle at $x_o$):
- $\nabla U_{\text{rep}}$ points away from $x_o$, so $F_{\text{rep}} = -\nabla U_{\text{rep}}$ pushes the robot away.
- The total force is $F = F_{\text{att}} + F_{\text{rep}}$, updated using Forward Euler ($v += F \Delta t$, $x += v \Delta t$).
- Intuition:
- Imagine a ball rolling down a hill: the hill’s shape is the potential $U$, and the ball follows the steepest downhill path ($-\nabla U$).
- The goal is a valley (low $U$), and obstacles are peaks (high $U$).
Interpretation of the Diagram
- Elements:
- The large gray circle likely represents an obstacle with high potential energy.
- The smaller circles might represent other obstacles or the robot itself.
- The $+$ symbol could indicate the goal $x_g$, a point of low potential energy.
- Implication:
- The robot (assumed as a point at $x$) starts somewhere in this space and moves toward the $+$ (goal) while avoiding the gray circle (obstacle).
- The potential field around the obstacle would be high, creating a repulsive force, while the field around the goal would be low, creating an attractive force.
Connection to Previous Discussions
- Reactive Force-Based Approach:
- The driving force $F_{\text{goal}} = \frac{v_g – v}{\tau}$ and avoidance forces $F_{\text{avoid}}$ are specific implementations of the forces derived from $-\nabla U$.
- The $\frac{v_g – v}{\tau}$ term can be seen as a velocity-based approximation of the attractive force, while $F_{\text{avoid}} = \frac{\max(d_H – d_{AO}, 0)}{d_{AO}} n_{AB}$ reflects the repulsive force scaled by distance.
- Forward Euler:
- The negative gradient $-\nabla U$ provides the force $F$, which is integrated using Forward Euler to update the robot’s motion, as seen in $v += F \Delta t$ and $x += v \Delta t$.
- Circle Example:
- The issue you raised (agents colliding before bouncing) might stem from the potential function’s design. If the repulsive potential only activates at close range (e.g., $\|x – x_o\| < d_0$), agents may collide before the force is strong enough. Increasing $d_0$ or $d_H$ could prevent this.
Example Calculation
Let’s compute a simple 2D example:
- Robot Position: $x = (0, 0)$
- Goal Position: $x_g = (2, 0)$
- Obstacle Position: $x_o = (1, 1)$
- Parameters: $k_{\text{att}} = 1$, $k_{\text{rep}} = 1$, $d_0 = 1.5$
- Attractive Potential:$$
U_{\text{att}} = \frac{1}{2} k_{\text{att}} \|x – x_g\|^2 = \frac{1}{2} \cdot 1 \cdot \sqrt{(0-2)^2 + (0-0)^2}^2 = \frac{1}{2} \cdot 4 = 2
$$
$$
\nabla U_{\text{att}} = k_{\text{att}} (x – x_g) = 1 \cdot (0-2, 0-0) = (-2, 0)
$$
$$
F_{\text{att}} = -\nabla U_{\text{att}} = (2, 0)
$$ - Repulsive Potential:
- Distance to obstacle: $\|x – x_o\| = \sqrt{(0-1)^2 + (0-1)^2} = \sqrt{2} \approx 1.41$
- Since $1.41 < 1.5$:$$
U_{\text{rep}} = \frac{1}{2} k_{\text{rep}} \left(\frac{1}{1.41} – \frac{1}{1.5}\right)^2 \approx \frac{1}{2} \cdot 1 \cdot (0.709 – 0.667)^2 \approx 0.0045
$$- $\nabla U_{\text{rep}}$ is complex but points toward $x_o$, so $F_{\text{rep}} = -\nabla U_{\text{rep}}$ points away (approximated as $k_{\text{rep}} \frac{x – x_o}{\|x – x_o\|^3}$ for small distances).
- $F_{\text{rep}} \approx 1 \cdot \frac{(0-1, 0-1)}{(\sqrt{2})^3} \approx \frac{(-1, -1)}{2.828} \approx (-0.354, -0.354)$
- Total Force:$$
F = F_{\text{att}} + F_{\text{rep}} \approx (2, 0) + (-0.354, -0.354) = (1.646, -0.354)
$$ - Update with Forward Euler ($\Delta t = 0.1$):$$
v_{\text{new}} = (0, 0) + (1.646, -0.354) \cdot 0.1 = (0.1646, -0.0354)
$$
$$
x_{\text{new}} = (0, 0) + (0.1646, -0.0354) \cdot 0.1 = (0.01646, -0.00354)
$$
The robot moves toward the goal while slightly adjusting to avoid the obstacle.

Diagram Interpretation
- Left Side:
- A black dot (likely the obstacle at $x_o$) with arrows radiating outward.
- These arrows represent $F_{\text{obs}}$, the repulsive force, pointing away from the obstacle in all directions. This aligns with $-\nabla U_{\text{obs}}$, which pushes the robot outward.
- Right Side:
- A 3D plot of a potential field, resembling a bowl or cone inverted over the obstacle.
- The height represents $U_{\text{obs}}$, increasing sharply near $x_o$ and flattening as distance increases.
- The gradient vectors (not shown but implied) point upward (toward higher $U$), so $-\nabla U_{\text{obs}}$ points downward and outward, matching the repulsive force.
Detailed Explanation of Each Point
1. Obstacle Repulsive Potential – Avoid Each Obstacle Located at $x_o$
- Potential Function:$$
U_{\text{obs}} = \frac{k}{2} \|x – x_o\|^{-2}
$$- $U_{\text{obs}}$: The repulsive potential energy due to an obstacle at $x_o$.
- $k$: A positive gain constant (same or different from the attractive $k$).
- $\|x – x_o\|$: The Euclidean distance between the robot’s position $x$ and the obstacle’s position $x_o$.
- $\|x – x_o\|^{-2}$: The inverse square of the distance, which is the “norm -2” you asked about.
- Note: This formula differs from the more common $\frac{1}{2} k \left(\frac{1}{\|x – x_o\|} – \frac{1}{d_0}\right)^2$ (seen in some APF variants), which includes a influence distance $d_0$ to limit the effect. The $\|x – x_o\|^{-2}$ form suggests a strong repulsion that increases rapidly as the robot approaches the obstacle.
- Force:$$
F_{\text{obs}} = -\nabla_x U_{\text{obs}} = k \|x – x_o\|^{-4} (x_o – x)
$$- $\nabla_x U_{\text{obs}}$: The gradient of the repulsive potential.
- $-\nabla_x U_{\text{obs}}$: The force, pushing the robot away from $x_o$.
- Derivation:
- Let $r = \|x – x_o\|$, so $U_{\text{obs}} = \frac{k}{2} r^{-2}$.
- The gradient of $U_{\text{obs}}$ involves the derivative of $r^{-2}$ with respect to $x$.
- $\frac{\partial r}{\partial x} = \frac{x – x_o}{r}$ (unit vector in the direction of $x – x_o$),
- $\frac{\partial}{\partial r} (r^{-2}) = -2 r^{-3}$,
- Using the chain rule, $\nabla_x U_{\text{obs}} = \frac{k}{2} \cdot (-2) r^{-3} \cdot \frac{x – x_o}{r} = -k r^{-4} (x – x_o)$,
- So $F_{\text{obs}} = -\nabla_x U_{\text{obs}} = k r^{-4} (x – x_o) = k \|x – x_o\|^{-4} (x – x_o)$.
- The direction $x_o – x$ (opposite of $x – x_o$) ensures repulsion, and the magnitude is adjusted.
- The “Norm -2” Question:
- The $\|x – x_o\|^{-2}$ in $U_{\text{obs}}$ means the potential energy decreases with the inverse square of the distance from the obstacle. This is unusual compared to the more typical inverse distance ($\|x – x_o\|^{-1}$) or the $\left(\frac{1}{\|x – x_o\|}\right)^2$ form with a cutoff.
- Why -2?:
- The exponent -2 in the potential leads to a -4 exponent in the force because the gradient involves differentiating $r^{-2}$, which introduces an additional $r^{-1}$ factor (e.g., $\frac{d}{dr} r^{-2} = -2 r^{-3}$, and the vector form scales by $r^{-1}$).
- This creates a very strong repulsion as $\|x – x_o\|$ approaches zero, which can help prevent collisions but may cause instability if not bounded.
- Comparison: The standard repulsive potential often uses $\|x – x_o\|^{-1}$ or a modified form to avoid infinite forces, with a cutoff at $d_0$. The $-2$ exponent here suggests a design choice for rapid escalation near obstacles.
- Intuition:
- The repulsive potential $U_{\text{obs}}$ is infinite at $x = x_o$ (since $\|x – x_o\|^{-2} \to \infty$ as $\|x – x_o\| \to 0$) and decreases sharply as the robot moves away.
- The force $F_{\text{obs}}$ grows with $\|x – x_o\|^{-4}$, meaning it becomes extremely strong very close to the obstacle, pushing the robot away forcefully.
Example Calculation
- Setup:
- $x = (0, 0)$, $x_g = (2, 0)$, $x_o = (1, 1)$
- $k = 1$ (same for both potentials)
- $\Delta t = 0.1$
- Attractive Force:$$
F_{\text{goal}} = k (x_g – x) = 1 \cdot ((2, 0) – (0, 0)) = (2, 0)
$$ - Repulsive Force:
- $\|x – x_o\| = \sqrt{(0-1)^2 + (0-1)^2} = \sqrt{2} \approx 1.41$
- $\|x – x_o\|^{-4} = (1.41)^{-4} \approx (1.41)^{-2} \cdot (1.41)^{-2} \approx 0.504 \cdot 0.504 \approx 0.254$
- $x_o – x = (1, 1) – (0, 0) = (1, 1)$
- $F_{\text{obs}} = k \|x – x_o\|^{-4} (x_o – x) = 1 \cdot 0.254 \cdot (1, 1) \approx (0.254, 0.254)$
- Total Force:$$
F_{\text{total}} = F_{\text{goal}} + F_{\text{obs}} = (2, 0) + (0.254, 0.254) = (2.254, 0.254)
$$ - Update:$$
v_{\text{new}} = (0, 0) + (2.254, 0.254) \cdot 0.1 = (0.2254, 0.0254)
$$
$$
x_{\text{new}} = (0, 0) + (0.2254, 0.0254) \cdot 0.1 = (0.02254, 0.00254)
$$
The robot moves toward the goal, slightly deflected by the obstacle.
Why $\|x – x_o\|^{-2}$ and $\|x – x_o\|^{-4}$?
- Potential Design:
- The $-2$ exponent in $U_{\text{obs}}$ creates a potential that diverges as the robot approaches the obstacle, ensuring strong avoidance.
- The resulting $-4$ in $F_{\text{obs}}$ amplifies this effect, making the force grow very quickly near $x_o$, which can be useful but risky (may cause oscillations).
- Comparison to Standard APF:
- The typical repulsive potential uses $\|x – x_o\|^{-1}$ or a cutoff to avoid infinite forces. The $-2$ form here is less common and might be a typo or a specific design choice for this context (e.g., to match a particular simulation).
- Improvement:
- To avoid the circle collision issue, consider $U_{\text{obs}} = \frac{k}{2} \left(\frac{1}{\|x – x_o\|} – \frac{1}{d_0}\right)^2$ with $d_0 > 0$, which limits the force beyond a safe distance.
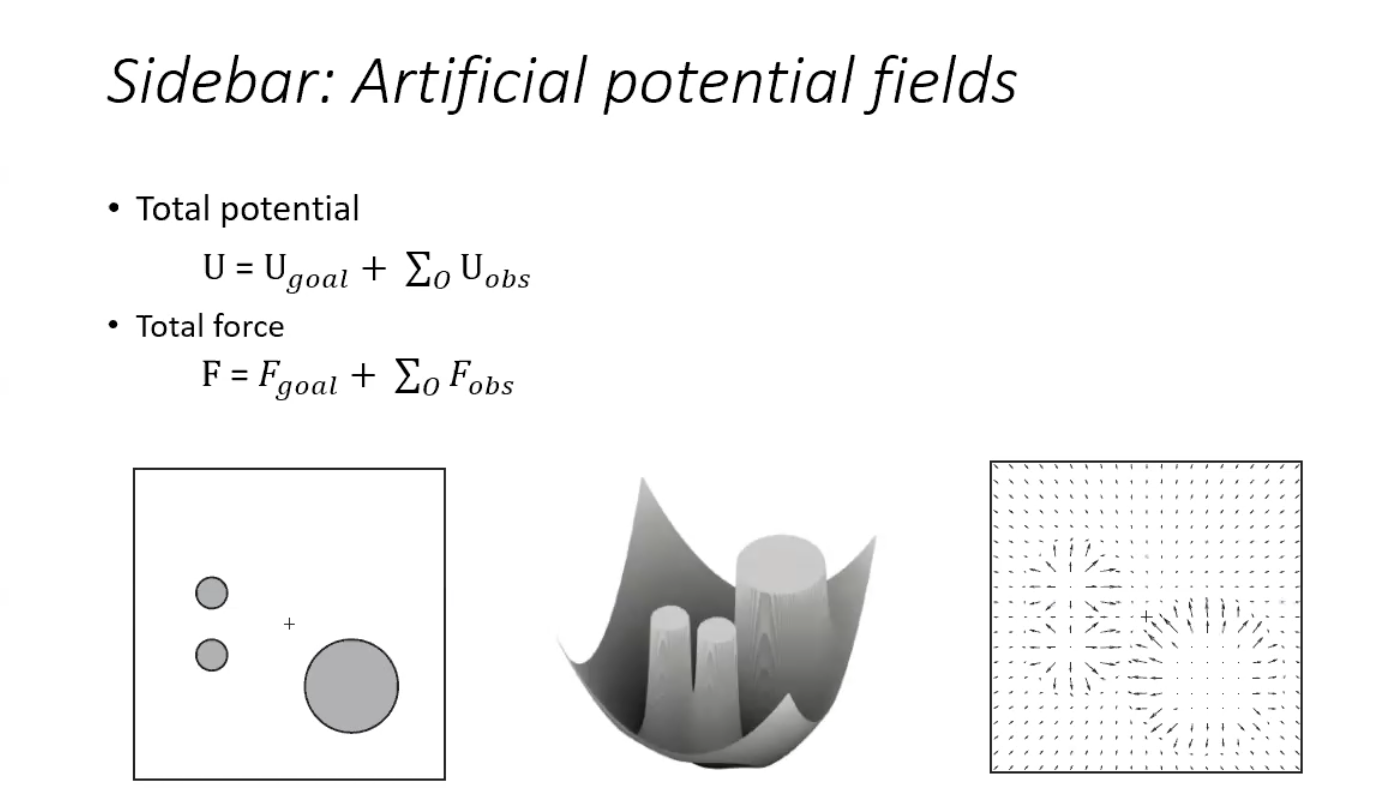
Let’s explore this slide on Artificial Potential Fields (APF), which builds on the previous slides by defining the total potential and total force acting on a robot in a 2D environment. This slide integrates the attractive potential (toward the goal) and repulsive potentials (from obstacles) to create a comprehensive navigation strategy. I’ll break down the concepts, interpret the diagrams, and connect them to our earlier discussions, providing examples to deepen your understanding.
Overview
Artificial Potential Fields guide a robot by combining a potential energy landscape that attracts it to a goal and repels it from obstacles. The total potential $U$ is the sum of the goal attractive potential $U_{\text{goal}}$ and the repulsive potentials from all obstacles $U_{\text{obs}}$. The total force $F$ is derived as the negative gradient of this total potential, guiding the robot’s motion. This ties directly to the reactive force-based approach we’ve been analyzing.
Detailed Explanation of Each Point
1. Total Potential
- Formula:$$
U = U_{\text{goal}} + \sum_o U_{\text{obs}}
$$- $U$: The total potential energy at the robot’s position $x$.
- $U_{\text{goal}}$: The attractive potential pulling the robot toward the goal $x_g$, defined in the previous slide as $U_{\text{goal}} = \frac{1}{2} k (x – x_g)^2$ (likely meaning $\frac{1}{2} k \|x – x_g\|^2$).
- $U_{\text{obs}}$: The repulsive potential from each obstacle $o$ located at $x_o$, defined as $U_{\text{obs}} = \frac{k}{2} \|x – x_o\|^{-2}$.
- $\sum_o$: Summation over all obstacles in the environment.
- Interpretation:
- The total potential $U$ creates an energy landscape where the robot seeks a low-energy state.
- $U_{\text{goal}}$ forms a parabolic well at the goal $x_g$, encouraging movement toward it.
- Each $U_{\text{obs}}$ creates a peak near an obstacle $x_o$, repelling the robot as it approaches.
- The combination shapes the robot’s path, balancing attraction and repulsion.
2. Total Force
- Formula:$$
F = F_{\text{goal}} + \sum_o F_{\text{obs}}
$$- $F$: The total force acting on the robot.
- $F_{\text{goal}}$: The attractive force toward the goal, given by $F_{\text{goal}} = -\nabla_x U_{\text{goal}} = k (x_g – x)$.
- $F_{\text{obs}}$: The repulsive force from each obstacle, given by $F_{\text{obs}} = -\nabla_x U_{\text{obs}} = k \|x – x_o\|^{-4} (x_o – x)$.
- $\sum_o$: Summation of repulsive forces from all obstacles.
- Interpretation:
- The total force $F$ is the vector sum of the attractive force and all repulsive forces.
- This force is used with Forward Euler integration ($v += F \Delta t$, $x += v \Delta t$) to update the robot’s velocity and position.
- The negative gradient ensures the robot moves downhill in the potential landscape, toward the goal while avoiding obstacles.
- Relationship to Potential:
- Since $F = -\nabla_x U$ and $U = U_{\text{goal}} + \sum_o U_{\text{obs}}$, the total force is the negative gradient of the total potential:$$
F = -\nabla_x (U_{\text{goal}} + \sum_o U_{\text{obs}}) = -\nabla_x U_{\text{goal}} – \sum_o \nabla_x U_{\text{obs}} = F_{\text{goal}} + \sum_o F_{\text{obs}}
$$ - This confirms the additive nature of the forces.
- Since $F = -\nabla_x U$ and $U = U_{\text{goal}} + \sum_o U_{\text{obs}}$, the total force is the negative gradient of the total potential:$$
Interpretation of the Diagrams
Left Diagram (2D Environment)
- Elements:
- A large gray circle represents an obstacle.
- Two smaller circle represent obstacle or the robot.
- A $+$ symbol marks the goal $x_g$.
- Implication:
- This is a snapshot of the robot’s environment, where the potential field will be calculated.
- The robot (assumed at $x$) will experience an attractive force toward $+$ and repulsive forces away from the gray circle.
Middle Diagram (3D Potential Landscape)
- Elements:
- A 3D surface with a valley (low potential) and peaks (high potential).
- Two cylindrical peaks likely represent obstacles, creating repulsive potential hills.
- The valley slopes toward a lower point, representing the attractive potential toward the goal.
- Implication:
- The surface visualizes $U = U_{\text{goal}} + \sum_o U_{\text{obs}}$.
- The robot moves downhill (following $-\nabla U$), navigating around the peaks (obstacles) toward the valley’s bottom (goal).
Right Diagram (Force Field)
- Elements:
- A 2D grid with arrows pointing in various directions.
- Two clusters of arrows: one radiating outward (repulsive force from an obstacle) and another converging inward (attractive force toward the goal).
- Implication:
- The arrows represent the vector field of $F = F_{\text{goal}} + \sum_o F_{\text{obs}}$.
- Near an obstacle, arrows point outward (repulsion), while near the goal, they point inward (attraction).
- The robot follows these arrows, adjusting its path based on the combined force.
Example Calculation
- Setup:
- $x = (0, 0)$, $x_g = (2, 0)$, $x_o = (1, 1)$ (one obstacle)
- $k = 1$, $\Delta t = 0.1$
- Attractive Force:$$
F_{\text{goal}} = k (x_g – x) = 1 \cdot ((2, 0) – (0, 0)) = (2, 0)
$$ - Repulsive Force:
- $\|x – x_o\| = \sqrt{(0-1)^2 + (0-1)^2} = \sqrt{2} \approx 1.41$
- $\|x – x_o\|^{-4} = (1.41)^{-4} \approx 0.254$
- $x_o – x = (1, 1) – (0, 0) = (1, 1)$
- $F_{\text{obs}} = k \|x – x_o\|^{-4} (x_o – x) = 1 \cdot 0.254 \cdot (1, 1) = (0.254, 0.254)$
- Total Force:$$
F = F_{\text{goal}} + F_{\text{obs}} = (2, 0) + (0.254, 0.254) = (2.254, 0.254)
$$ - Update:$$
v_{\text{new}} = (0, 0) + (2.254, 0.254) \cdot 0.1 = (0.2254, 0.0254)
$$
$$
x_{\text{new}} = (0, 0) + (0.2254, 0.0254) \cdot 0.1 = (0.02254, 0.00254)
$$
The robot moves toward the goal, slightly deflected by the obstacle.
How to Learn and Apply
- Code It:
- Implement $U = U_{\text{goal}} + \sum_o U_{\text{obs}}$ and $F = F_{\text{goal}} + \sum_o F_{\text{obs}}$ in Python.
- Example:
k = 1 U_goal = 0.5 * k * np.linalg.norm(x - x_g)**2 U_obs = 0.5 * k / (np.linalg.norm(x - x_o)**2) F_goal = k * (x_g - x) F_obs = k * (1 / (np.linalg.norm(x - x_o)**4)) * (x_o - x) F_total = F_goal + F_obs
- Experiment:
- Test with multiple obstacles and adjust $k$ or add a $d_0$ cutoff.
- Visualize:
- Plot the potential surface and force field using matplotlib.

Let’s dive into this slide on Predictive Forces, which introduces an advanced concept in the reactive force-based approach to robot navigation. This idea extends the traditional avoidance force by considering the future positions of the agent and its neighbor, rather than relying solely on their current positions. This predictive approach aims to improve collision avoidance, especially in dynamic environments where agents are moving. I’ll break down the concept, interpret the diagram, and connect it to our previous discussions, providing examples to enhance your understanding.
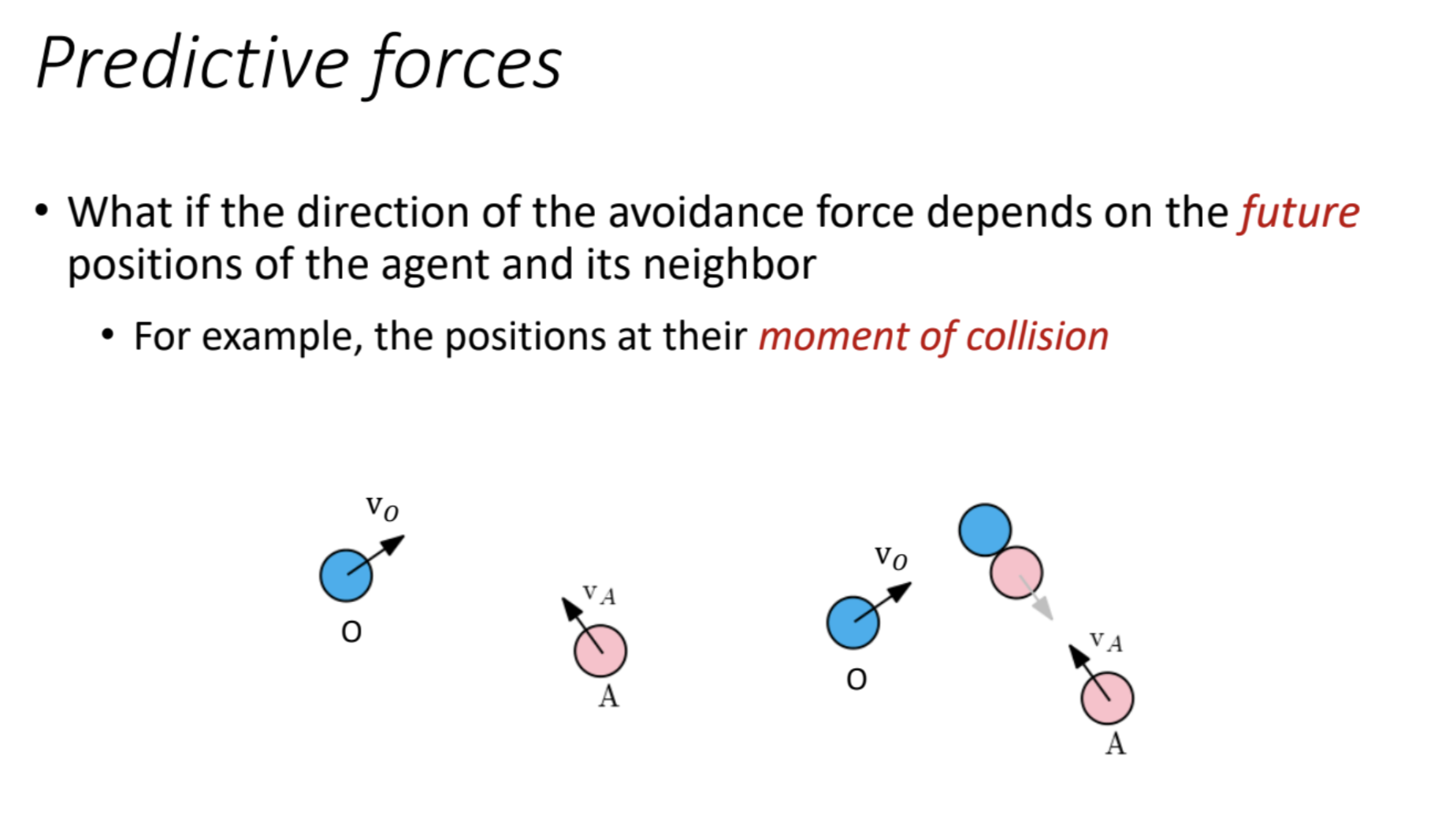
Let’s dive into this slide on Predictive Forces, which builds on the previous introduction to predictive avoidance by specifying that the direction of the avoidance force depends on the future positions of the agent and its neighbor, with a particular example focusing on their positions at the moment of collision. This approach enhances collision avoidance by anticipating the exact point where a collision might occur, allowing the agent to adjust its path proactively. I’ll break down the concept, interpret the diagram, and connect it to our prior discussions, including a detailed example to clarify the idea.
Overview
This slide advances the predictive force concept by proposing that the avoidance force direction is based on the predicted positions of the agent (A) and its neighbor (O) at the moment they would collide, if no action is taken. This is a refinement of the earlier predictive idea (using a fixed time horizon), aiming to compute the collision point and derive a force to avoid it. This is particularly relevant for dynamic environments, addressing issues like the circle example where agents collided before reacting.
Detailed Explanation
Key Points:
- What if the direction of the avoidance force depends on the future positions of the agent and its neighbor
- This reiterates the idea from the previous slide: instead of relying on current positions, the avoidance force anticipates future states.
- The focus here is on using predictive modeling to determine the optimal avoidance direction.
- For example, the positions at their moment of collision
- The slide suggests calculating the avoidance force based on the positions where A and O would collide if they continue along their current velocities.
- This requires predicting the collision point by analyzing the trajectories defined by $v_A$ (agent’s velocity) and $v_O$ (neighbor’s velocity), then designing the force to steer A away from that point.
- Collision Prediction:
- The moment of collision occurs when the relative positions of A and O, adjusted by their velocities, result in zero distance between them.
- Mathematically, we solve for the time $t_c$ when $\| (x_A + v_A t_c) – (x_O + v_O t_c) \| = 0$, assuming linear motion and constant velocities.
- Avoidance Force Direction:
- Once the collision position is estimated, the avoidance force direction can be perpendicular to the line connecting the current position to the collision point, or along the relative velocity vector adjusted for avoidance.
- The magnitude might still depend on the current distance or time to collision.
Interpretation of the Diagram
- Elements:
- O (Blue Circle): The neighbor (e.g., obstacle or another agent) with velocity $v_O$ (black arrow pointing right).
- A (Pink Circle): The agent with velocity $v_A$ (black arrow pointing up and right in the first case, down in the second).
- Dashed Circles: Represent the predicted future positions of A and O at the moment of collision.
- Two scenarios are shown:
- Left Scenario: $v_O$ (right) and $v_A$ (up and right) suggest a potential collision if their paths cross.
- Right Scenario: $v_O$ (right) and $v_A$ (down) show a different relative motion, with the collision point shifted.
- Implication:
- The dashed circles indicate the predicted collision positions. For example:
- In the left scenario, if A continues up and right and O continues right, they might collide at the dashed position.
- In the right scenario, A’s downward $v_A$ adjusts the collision point.
- The avoidance force (not shown) would direct A to veer away from this collision point, e.g., left or right, depending on the geometry.
- The dashed circles indicate the predicted collision positions. For example:

How Predictive Forces at Collision Work
Let’s formalize the process:
- Current States:
- Agent A: Position $x_A$, velocity $v_A$.
- Neighbor O: Position $x_O$, velocity $v_O$.
- Collision Time Calculation:
- The relative velocity is $v_{\text{rel}} = v_A – v_O$.
- The relative position is $x_{\text{rel}} = x_A – x_O$.
- Collision occurs when $x_{\text{rel}} + v_{\text{rel}} t_c = 0$, or $(x_A – x_O) + (v_A – v_O) t_c = 0$.
- Solving for $t_c$:
- $v_{\text{rel}} t_c = -(x_A – x_O)$
- $t_c = -\frac{x_A – x_O}{v_A – v_O}$ (dot product if vectors, requires $v_{\text{rel}} \neq 0$ and checking feasibility).
- If $t_c > 0$ and within a reasonable horizon, it’s a valid collision time.
- Collision Position:
- $x_{\text{collision}} = x_A + v_A t_c$ (or $x_O + v_O t_c$, both should be the same).
- Avoidance Force Direction:
- The direction $n_{\text{avoid}}$ could be perpendicular to $x_{\text{collision}} – x_A$, or based on the cross product of $v_A$ and $v_O$ to determine a safe sidestep.
- Example: $n_{\text{avoid}} = \frac{(v_A \times v_O)}{\|(v_A \times v_O)\|}$ (in 2D, use a rotation or perpendicular vector).
- Magnitude:
- Could be proportional to $1/t_c$ (urgency increases as collision nears) or $1/\|x_A – x_O\|$ (current distance).
Example Calculation
- Setup:
- $x_A = (0, 0)$, $v_A = (1, 1)$ m/s (up and right).
- $x_O = (2, 0)$, $v_O = (-1, 0)$ m/s (left).
- Assume 2D plane, $\Delta t = 0.1$ s.
- Relative Motion:
- $x_{\text{rel}} = (0 – 2, 0 – 0) = (-2, 0)$
- $v_{\text{rel}} = (1 – (-1), 1 – 0) = (2, 1)$
- $t_c = -\frac{x_{\text{rel}} \cdot v_{\text{rel}}}{|v_{\text{rel}}|^2}$ (dot product method):
- $x_{\text{rel}} \cdot v_{\text{rel}} = (-2) \cdot 2 + 0 \cdot 1 = -4$
- $|v_{\text{rel}}|^2 = 2^2 + 1^2 = 5$
- $t_c = -\frac{-4}{5} = 0.8$ s (positive, feasible).
- Collision Position:
- $x_{\text{collision}} = x_A + v_A t_c = (0, 0) + (1, 1) \cdot 0.8 = (0.8, 0.8)$
- Avoidance Direction:
- Relative vector to collision: $x_{\text{collision}} – x_A = (0.8, 0.8)$
- Perpendicular vector (rotate 90°): $n_{\text{avoid}} = (-0.8, 0.8)$ or normalize $\frac{(-0.8, 0.8)}{\sqrt{1.28}} \approx (-0.707, 0.707)$.
- Avoidance Force:
- Current distance $d_{AO} = \sqrt{(2-0)^2 + (0-0)^2} = 2$
- $F_{\text{avoid}} = \frac{\max(2 – 2, 0)}{2} n_{\text{avoid}} = 0$ (if $d_H = 2$, adjust $d_H > 2$).
- With $d_H = 3$: $F_{\text{avoid}} = \frac{\max(3 – 2, 0)}{2} \cdot (-0.707, 0.707) = \frac{1}{2} \cdot (-0.707, 0.707) \approx (-0.353, 0.353)$.
- Update:
- If $F_{\text{goal}} = (2, 0)$, $F_{\text{total}} = (2, 0) + (-0.353, 0.353) = (1.647, 0.353)$.
- $v_{\text{new}} = (0, 0) + (1.647, 0.353) \cdot 0.1 = (0.1647, 0.0353)$.
This steers A leftward to avoid the collision at $(0.8, 0.8)$.
Connection to Previous Discussions
- Reactive Forces:
- Traditional $F_{\text{avoid}}$ used current $n_{AB}$, leading to late reactions. This method predicts $x_{\text{collision}}$, addressing the circle example’s issue.
- Previous Predictive Forces:
- The earlier slide used a fixed $\Delta t_{\text{predict}}$, while this focuses on $t_c$, offering a more precise collision-avoidance strategy.
- Artificial Potential Fields:
- The repulsive force could be redefined using $x_{\text{collision}}$, enhancing the $U_{\text{obs}}$ model.
Advantages and Limitations
- Advantages:
- Precisely targets collision avoidance.
- Effective for intersecting trajectories.
- Limitations:
- Requires accurate $v_A$ and $v_O$, which may be noisy.
- Assumes linear motion, which may not hold for complex paths.
- Computation of $t_c$ can be unstable if velocities are parallel or near-zero.
Improving the Circle Example
- Apply Collision Prediction:
- Compute $t_c$ for each pair in the circle simulation.
- Use $n_{\text{avoid}}$ perpendicular to $x_{\text{collision}} – x_A$.
- Tune $d_H$: Set $d_H >$ max possible $d_{AO}$ to ensure early action.
- Validate Velocities: Use sensor data to refine $v_A$ and $v_O$.
How to Learn and Apply
- Code It:
- Implement collision time and avoidance direction:
v_rel = v_A - v_O x_rel = x_A - x_B t_c = -np.dot(x_rel, v_rel) / np.dot(v_rel, v_rel) if np.dot(v_rel, v_rel) != 0 else float('inf') x_collision = x_A + v_A * t_c n_avoid = np.array([- (x_collision[1] - x_A[1]), x_collision[0] - x_A[0]]) n_avoid = n_avoid / np.linalg.norm(n_avoid) F_avoid = (max(d_H - np.linalg.norm(x_A - x_B), 0) / np.linalg.norm(x_A - x_B)) * n_avoid
- Implement collision time and avoidance direction:
- Experiment:
- Test with varying $v_A$ and $v_O$ to observe path adjustments.
- Simulate:
- Use ROS/Gazebo with moving agents to validate.

Let’s dive into this slide titled Computing $\tau$, which details the mathematical process for determining the time to collision ($\tau$) between an agent $A$ and its neighbor $O$. This is a crucial step in the predictive forces approach we’ve been discussing, as it allows the agent to anticipate a collision and adjust its avoidance force proactively. I’ll break down each point, derive the quadratic equation, and connect this to our previous discussions, including an example to illustrate the process.
Overview
The slide provides a method to compute the exact time $\tau$ when two agents (or an agent and an obstacle) would collide, based on their relative positions, velocities, and sizes (radii). This time to collision is used to predict the collision point, which informs the direction of the avoidance force in the predictive forces framework. This approach improves upon reactive methods by enabling earlier collision avoidance, addressing issues like the circle example where agents collided before bouncing apart.
Detailed Explanation
1. Given an agent $A$ and its neighbor $O$, let
- Relative Displacement:$$
x = x_A – x_O
$$- $x_A$: Position of agent $A$.
- $x_O$: Position of neighbor $O$.
- $x$: The vector representing the relative displacement between $A$ and $O$.
- Relative Velocity:$$
v = v_A – v_O
$$- $v_A$: Velocity of agent $A$.
- $v_O$: Velocity of neighbor $O$.
- $v$: The relative velocity vector, indicating how $A$ is moving relative to $O$.
- Combined Radii:$$
r = r_A + r_O
$$- $r_A$: Radius of agent $A$.
- $r_O$: Radius of neighbor $O$.
- $r$: The sum of their radii, representing the distance at which a collision occurs (i.e., when the distance between their centers equals the sum of their radii, assuming circular agents).
2. Formally, a collision exists if
$$
\|x + v \tau\| = r
$$
- What This Means:
- This equation defines the condition for a collision at time $\tau$.
- $x + v \tau$: The relative position of $A$ and $O$ after time $\tau$, assuming constant velocities.
- $\|x + v \tau\|$: The distance between $A$ and $O$ at time $\tau$.
- A collision occurs when this distance equals $r$, meaning the agents’ boundaries touch (for circular agents, this is when their centers are $r$ apart).
- Intuition:
- If $A$ and $O$ continue moving with velocities $v_A$ and $v_O$, their relative motion is described by $v = v_A – v_O$.
- We need to find the time $\tau$ when the distance between them shrinks to $r$, indicating a collision.
3. Squaring and expanding, leads to the following quadratic equation for $\tau$
$$
(v \cdot v) \tau^2 + 2 (x \cdot v) \tau + (x \cdot x – r^2) = 0
$$
- Derivation:
- Start with the collision condition: $\|x + v \tau\| = r$.
- Square both sides to eliminate the norm:$$
\|x + v \tau\|^2 = r^2
$$ - Expand the left-hand side:$$
\|x + v \tau\|^2 = (x + v \tau) \cdot (x + v \tau)
$$
$$
= x \cdot x + 2 (x \cdot v \tau) + (v \tau) \cdot (v \tau)
$$
$$
= x \cdot x + 2 (x \cdot v) \tau + (v \cdot v) \tau^2
$$ - So the equation becomes:$$
x \cdot x + 2 (x \cdot v) \tau + (v \cdot v) \tau^2 = r^2
$$ - Rearrange to form a quadratic in $\tau$:$$
(v \cdot v) \tau^2 + 2 (x \cdot v) \tau + (x \cdot x – r^2) = 0
$$ - Here:
- $v \cdot v = \|v\|^2$: The squared magnitude of the relative velocity.
- $x \cdot v$: The dot product of the relative position and velocity.
- $x \cdot x = \|x\|^2$: The squared magnitude of the relative displacement.
- $r^2$: The squared sum of the radii.
- Quadratic Form:
- This is a standard quadratic equation $a \tau^2 + b \tau + c = 0$, where:
- $a = v \cdot v$
- $b = 2 (x \cdot v)$
- $c = x \cdot x – r^2$
- Solve for $\tau$ using the quadratic formula:$$
\tau = \frac{-b \pm \sqrt{b^2 – 4ac}}{2a}
$$
$$
\tau = \frac{-2 (x \cdot v) \pm \sqrt{(2 (x \cdot v))^2 – 4 (v \cdot v) (x \cdot x – r^2)}}{2 (v \cdot v)}
$$
$$
\tau = \frac{- (x \cdot v) \pm \sqrt{(x \cdot v)^2 – (v \cdot v) (x \cdot x – r^2)}}{v \cdot v}
$$
- This is a standard quadratic equation $a \tau^2 + b \tau + c = 0$, where:
- Choosing the Correct $\tau$:
- The equation may yield two solutions: one for the first collision (entering) and one for exiting the collision (if they pass through each other).
- We want the smallest positive $\tau$, as it represents the earliest collision time.
- If $\tau < 0$, it means the collision would have happened in the past (not relevant).
- If the discriminant $(x \cdot v)^2 – (v \cdot v) (x \cdot x – r^2) < 0$, there’s no real solution, meaning no collision occurs.
Example Calculation
- Setup:
- $x_A = (0, 0)$, $v_A = (1, 1)$ m/s (up and right).
- $x_O = (2, 0)$, $v_O = (-1, 0)$ m/s (left).
- $r_A = 0.5$, $r_O = 0.5$, so $r = 0.5 + 0.5 = 1$.
- Relative Displacement and Velocity:
- $x = x_A – x_O = (0 – 2, 0 – 0) = (-2, 0)$
- $v = v_A – v_O = (1 – (-1), 1 – 0) = (2, 1)$
- Quadratic Coefficients:
- $v \cdot v = 2^2 + 1^2 = 4 + 1 = 5$
- $x \cdot v = (-2) \cdot 2 + 0 \cdot 1 = -4$
- $x \cdot x = (-2)^2 + 0^2 = 4$
- $r^2 = 1^2 = 1$
- $x \cdot x – r^2 = 4 – 1 = 3$
- Quadratic Equation:$$
5 \tau^2 + 2 (-4) \tau + (4 – 1) = 0
$$
$$
5 \tau^2 – 8 \tau + 3 = 0
$$ - Solve for $\tau$:
- $a = 5$, $b = -8$, $c = 3$
- Discriminant: $b^2 – 4ac = (-8)^2 – 4 \cdot 5 \cdot 3 = 64 – 60 = 4$
- $\tau = \frac{-b \pm \sqrt{b^2 – 4ac}}{2a} = \frac{8 \pm \sqrt{4}}{2 \cdot 5} = \frac{8 \pm 2}{10}$
- $\tau_1 = \frac{10}{10} = 1$, $\tau_2 = \frac{6}{10} = 0.6$
- Smallest positive $\tau = 0.6$ s.
- Collision Position:
- At $\tau = 0.6$:
- $x_{A_{\text{collision}}} = x_A + v_A \tau = (0, 0) + (1, 1) \cdot 0.6 = (0.6, 0.6)$
- $x_{O_{\text{collision}}} = x_O + v_O \tau = (2, 0) + (-1, 0) \cdot 0.6 = (1.4, 0)$
- Relative distance: $\|(0.6, 0.6) – (1.4, 0)\| = \sqrt{(0.6 – 1.4)^2 + (0.6 – 0)^2} = \sqrt{0.64 + 0.36} = 1 = r$, confirming collision.
- At $\tau = 0.6$:
- Avoidance Force:
- Use $x_{\text{collision}}$ to compute the avoidance direction (as in the previous slide), e.g., perpendicular to $x_{A_{\text{collision}}} – x_A$.
Connection to Previous Discussions
- Predictive Forces:
- This slide provides the exact $\tau$ for the “moment of collision” approach, refining the fixed-time prediction ($\Delta t_{\text{predict}}$).
- The computed $\tau$ informs the collision position, which adjusts the avoidance force direction.
- Circle Example:
- The collision issue (agents touching before bouncing) can be mitigated by using $\tau$ to predict collisions early and adjust paths proactively.
- Artificial Potential Fields:
- The repulsive potential $U_{\text{obs}}$ could incorporate $\tau$, making the force stronger as $\tau$ decreases (closer to collision).
Advantages and Limitations
- Advantages:
- Precise prediction of collision time.
- Enables proactive avoidance, reducing collisions.
- Limitations:
- Assumes constant velocities, which may not hold in dynamic environments.
- If $v \cdot v = 0$ (no relative motion), the equation fails (requires special handling).
- Negative or imaginary $\tau$ indicates no collision, needing conditional checks.
Improving the Circle Example
- Compute $\tau$:
- For each pair of agents in the circle simulation, calculate $\tau$.
- Adjust Force:
- Use $\tau$ to predict collision positions and set $n_{\text{avoid}}$.
- Early Action:
- Increase $d_H$ or scale the force by $1/\tau$ to act sooner.

How to Learn and Apply
- Code It:
- Implement the quadratic solver for $\tau$:
x = x_A - x_O v = v_A - v_O r = r_A + r_O a = np.dot(v, v) b = 2 * np.dot(x, v) c = np.dot(x, x) - r**2 if a == 0: # Handle no relative motion tau = float('inf') else: discriminant = b**2 - 4 * a * c if discriminant < 0: tau = float('inf') # No collision else: tau1 = (-b + np.sqrt(discriminant)) / (2 * a) tau2 = (-b - np.sqrt(discriminant)) / (2 * a) tau = min(tau1, tau2) if tau1 > 0 and tau2 > 0 else max(tau1, tau2) if tau1 > 0 or tau2 > 0 else float('inf')
- Implement the quadratic solver for $\tau$:
- Experiment:
- Test with different $v_A$, $v_O$, and radii to observe $\tau$.
- Simulate:
- Integrate into the circle simulation to see improved avoidance.

Based on the image’s logic for computing $\tau$ and the need to handle the case where one solution is negative and the other is non-negative (setting $\tau = 0$ for current collision), I’ll rewrite the code. I’ll use the variable names implied by the image context ($\tau$, $d$, etc.) and ensure the logic aligns with the provided rules.
- Integrate into the circle simulation to see improved avoidance.
Improved Code
This version:
- Uses the variable names from the image context where applicable.
- Correctly handles the case of one negative and one non-negative solution by setting $\tau = 0$ for current collision.
- Follows the image’s conditions for no collision, both negative solutions, and both non-negative solutions.
- Assumes the quadratic equation is derived from relative motion (as in the original code), with coefficients $a$, $b$, and $c$.
import numpy as np
# Relative position, velocity, and sum of radii
x = x_A - x_O # Relative position vector
v = v_A - v_O # Relative velocity vector
r = r_A + r_O # Sum of radii
# Compute coefficients of the quadratic equation a*tau^2 + b*tau + c = 0
a = np.dot(v, v) # Dot product of relative velocity
b = 2 * np.dot(x, v) # Twice the dot product of relative position and velocity
c = np.dot(x, x) - r**2 # Dot product of relative position minus squared sum of radii
# Initialize tau as undefined (infinity)
tau = float('inf')
if a == 0: # Handle no relative motion
tau = float('inf')
else:
# Compute the discriminant
d = b**2 - 4 * a * c
if d < 0: # No real solutions (no collision)
tau = float('inf')
elif d == 0: # One double solution (no collision)
tau = float('inf')
else: # Two distinct solutions
# Compute the two solutions
tau1 = (-b + np.sqrt(d)) / (2 * a)
tau2 = (-b - np.sqrt(d)) / (2 * a)
# Check the signs of the solutions according to the image logic
if tau1 < 0 and tau2 < 0: # Both solutions negative, no collision
tau = float('inf')
elif (tau1 < 0 and tau2 >= 0) or (tau2 < 0 and tau1 >= 0): # One negative, one non-negative, currently colliding
tau = 0
elif tau1 >= 0 and tau2 >= 0: # Both non-negative, collision at minimum positive time
tau = min(tau1, tau2)
print(f"Collision time tau = {tau}")
Explanation
- Variable Names:
- Used $d$ for the discriminant to match the image’s notation.
- Kept $\tau$ as the collision time variable, aligning with the image’s focus on computing $\tau$.
- Retained $x$, $v$, and $r$ from the original code, assuming they represent relative position, velocity, and radii sum, respectively.
- Logic Alignment with Image:
- No solution ($d < 0$) or double solution ($d = 0$): Sets $\tau = \text{float(‘inf’)}$, matching “no collision, $\tau$ undefined.”
- Both solutions negative: Checks if both $\tau_1 < 0$ and $\tau_2 < 0$, sets $\tau = \text{float(‘inf’)}$, matching “no collision, $\tau$ undefined.”
- One negative, one non-negative: Explicitly checks if one solution is negative and the other is non-negative (or zero), sets $\tau = 0$, matching “currently colliding, $\tau = 0$.”
- Both non-negative: Sets $\tau = \min(\tau_1, \tau_2)$, matching “collision occurs at $\tau = \min(\tau’, \tau”)$.”
- Handling Edge Cases:
- The code includes a check for $a == 0$ (no relative motion), setting $\tau = \text{float(‘inf’)}$.
- The discriminant check ($d < 0$, $d = 0$) ensures proper handling of no real or double roots.
Notes
- This code assumes $x_A$, $x_O$, $v_A$, $v_O$, $r_A$, and $r_O$ are defined elsewhere as numpy arrays or compatible vectors.
- The use of $\text{np.dot}$ implies vector operations, suitable for 2D or 3D collision detection.
- If $\tau = 0$ is detected, it indicates the objects are currently intersecting, which aligns with the image’s intent.
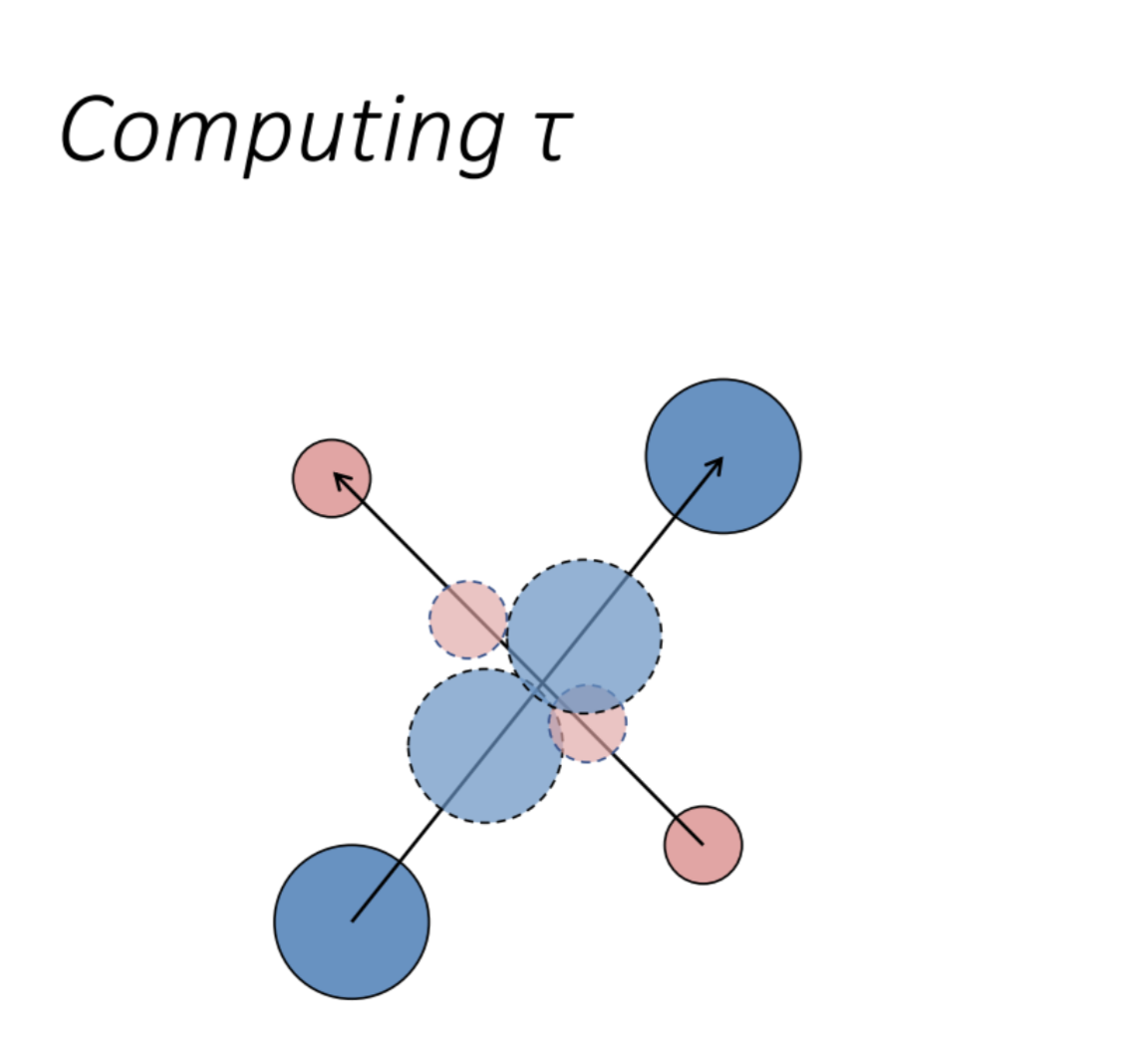


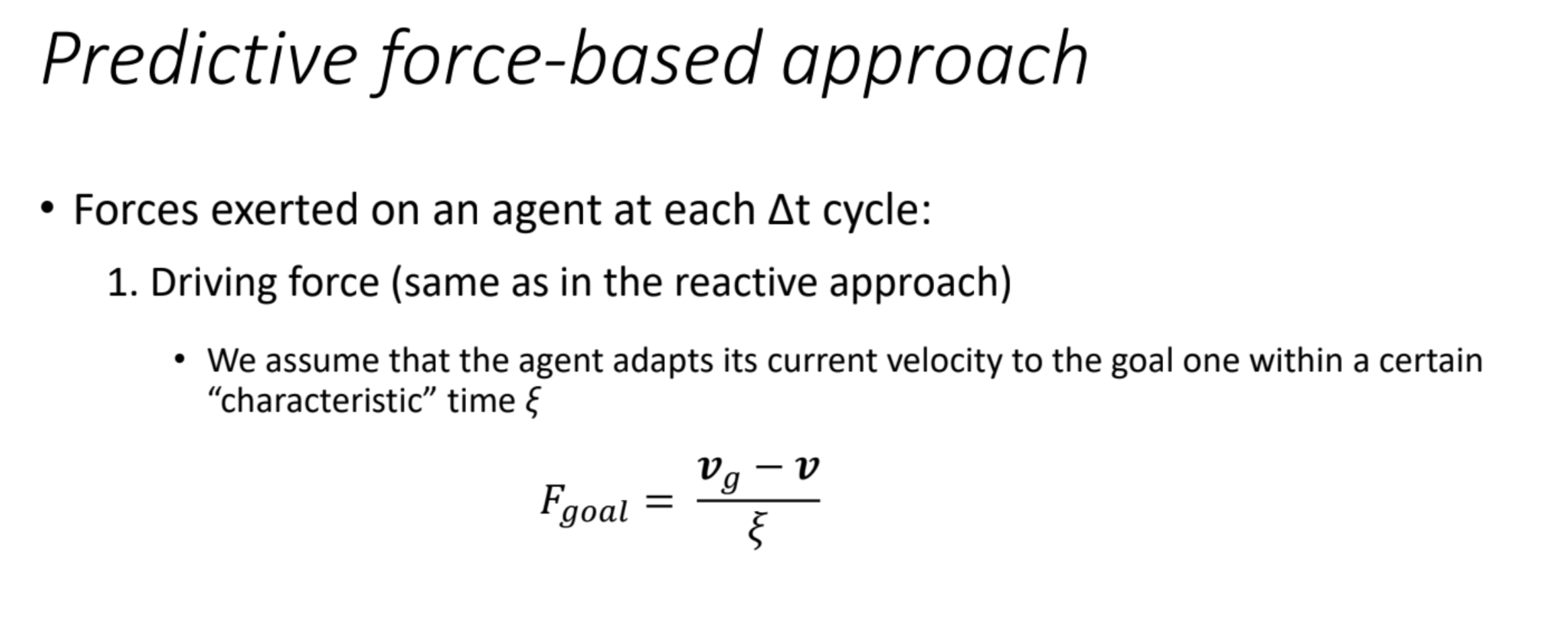
Explanation of the Slide: Predictive Force-Based Approach
This slide introduces a predictive force-based approach for navigating agents (e.g., robots) in a robotic system. This method focuses on how forces are applied to an agent at each time step ($\Delta t$) to guide its movement. Here’s a breakdown of the content:
- Forces Exerted on an Agent at Each $\Delta t$ Cycle:
- The approach considers the forces acting on the agent during each discrete time interval ($\Delta t$). These forces help determine how the agent moves or adjusts its path.
- 1. Driving Force (Same as in the Reactive Approach):
- The driving force is a key component, and it is identical to the one used in a reactive approach. In robotics, a reactive approach typically involves immediate responses to the environment (e.g., avoiding obstacles or moving toward a goal based on current sensor data).
- The slide specifies an assumption: the agent adapts its current velocity ($v$) to a desired goal velocity ($v_g$) within a certain “characteristic” time $\xi$ (a parameter representing how quickly the agent can adjust its velocity).
- Formula for the Driving Force ($F_{goal}$):
- The driving force is given by:$$
F_{goal} = \frac{v_g – v}{\xi}
$$ - Interpretation:
- $v_g$: The desired velocity vector toward the goal.
- $v$: The agent’s current velocity vector.
- $\xi$: The characteristic time, which acts as a damping factor or time constant. A smaller $\xi$ means the agent adjusts its velocity more quickly, while a larger $\xi$ indicates a slower adaptation.
- The expression $v_g – v$ represents the velocity difference (error) that the agent needs to correct to reach the goal velocity.
- Dividing by $\xi$ scales this correction, turning it into a force that drives the agent toward the goal over time.
- The driving force is given by:$$
- Conceptual Insight:
- This predictive approach likely anticipates future states by assuming the agent will gradually align its velocity with the goal velocity, rather than reacting instantly. This contrasts with purely reactive methods by incorporating a predictive element based on the characteristic time $\xi$.
- The force $F_{goal}$ can be thought of as a proportional control term in a control system, where the agent adjusts its motion proportional to the velocity error, moderated by $\xi$.
This approach is useful in robotics navigation because it provides a smooth transition toward the goal, avoiding abrupt changes that might occur in purely reactive systems. It also sets the stage for combining this driving force with other forces (e.g., collision avoidance) in a more comprehensive navigation strategy.
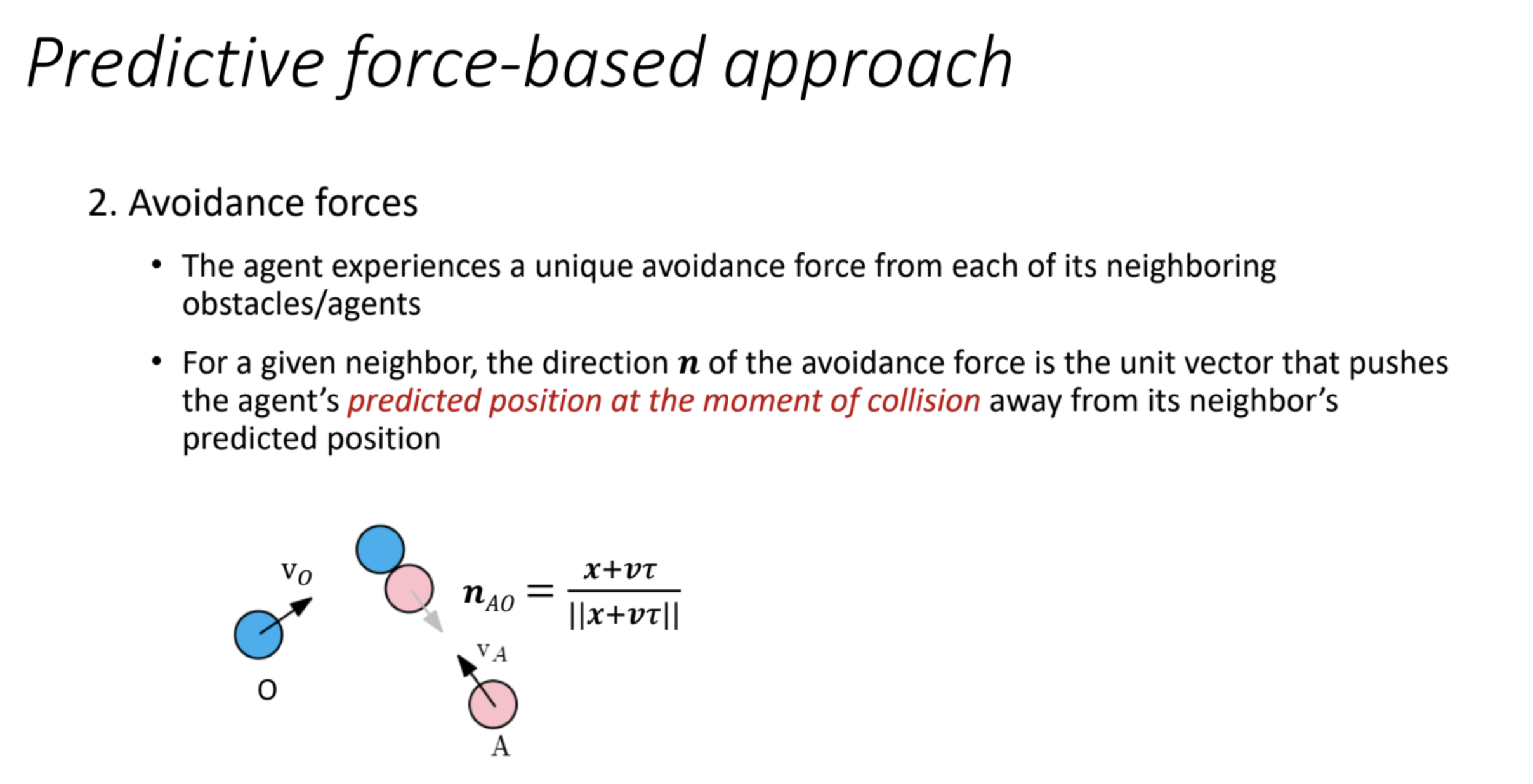
Explanation of the Slide: Predictive Force-Based Approach (Avoidance Forces)
This slide continues the discussion on the predictive force-based approach for robotic navigation, focusing on avoidance forces. These forces are crucial for preventing collisions between agents or with obstacles. Here’s a detailed breakdown:
- Avoidance Forces:
- The slide explains that each agent experiences a unique avoidance force from each of its neighboring agents or obstacles. This means that for every potential collision (with another agent or obstacle), the agent calculates a specific force to steer itself away.
- Direction of the Avoidance Force ($n$):
- For a given neighbor (agent or obstacle), the direction of the avoidance force is represented by a unit vector $n$.
- This vector $n$ is defined such that it pushes the agent’s predicted position at the moment of collision away from the neighbor’s predicted position at that same moment.
- The formula for $n$ is given as:$$
n_{A0} = \frac{x + v \tau}{\|x + v \tau\|}
$$- Variables:
- $x$: The relative position vector between the agent (A) and the neighbor (O), i.e., $x = x_A – x_O$.
- $v$: The relative velocity vector between the agent and the neighbor, i.e., $v = v_A – v_O$.
- $\tau$: The predicted time to collision, which we previously computed in the code for collision detection (refer to the earlier slides where $\tau$ was calculated using the quadratic equation).
- $x + v \tau$: This represents the relative position of the agent with respect to the neighbor at the predicted time of collision ($\tau$). It’s calculated assuming both agents continue moving with their current velocities ($v_A$ and $v_O$).
- $\|x + v \tau\|$: The magnitude (norm) of the relative position vector at the time of collision, which normalizes the vector to make $n_{A0}$ a unit vector (length 1).
- Interpretation:
- The vector $x + v \tau$ points from the neighbor (O) to the agent (A) at the moment of collision.
- Dividing by its magnitude ensures $n_{A0}$ is a unit vector, giving only the direction of the avoidance force.
- This direction is designed to push agent A away from agent O at the predicted collision point, helping A avoid the collision.
- Variables:
- Diagram Explanation:
- The diagram shows two agents:
- Agent O (blue circle) with velocity $v_O$.
- Agent A (red circle) with velocity $v_A$.
- The vector $n_{A0}$ (gray arrow) points from agent O toward agent A, indicating the direction in which agent A should be pushed to avoid agent O.
- The relative position $x$ and relative velocity $v$ are used to compute the predicted collision point, and $n_{A0}$ is derived from that.
- The diagram shows two agents:
- Conceptual Insight:
- Unlike reactive approaches that might apply avoidance forces based on current distances (e.g., repulsive forces that increase as agents get closer), this predictive method looks ahead to the moment of collision ($\tau$).
- By using the predicted positions at the time of collision, the avoidance force is more proactive, aiming to steer the agent away before the collision happens.
- The use of a unit vector ensures that the direction of avoidance is clear, while the magnitude of the avoidance force can be scaled separately (likely in a later step, not shown in this slide).
- Connection to Previous Slides:
- The $\tau$ used here ties back to the collision detection logic (from the “Computing $\tau$” slide). That slide provided the method to calculate the time to collision between two agents, which is now used to predict where the agents will be at that time.
- The avoidance force complements the driving force ($F_{goal}$) introduced earlier, creating a combined strategy where the agent is driven toward its goal while simultaneously avoiding collisions.
This predictive avoidance mechanism is a key feature in robotic navigation, especially in dynamic environments with multiple moving agents. It ensures safer and smoother navigation by anticipating collisions rather than reacting to them after they become imminent.
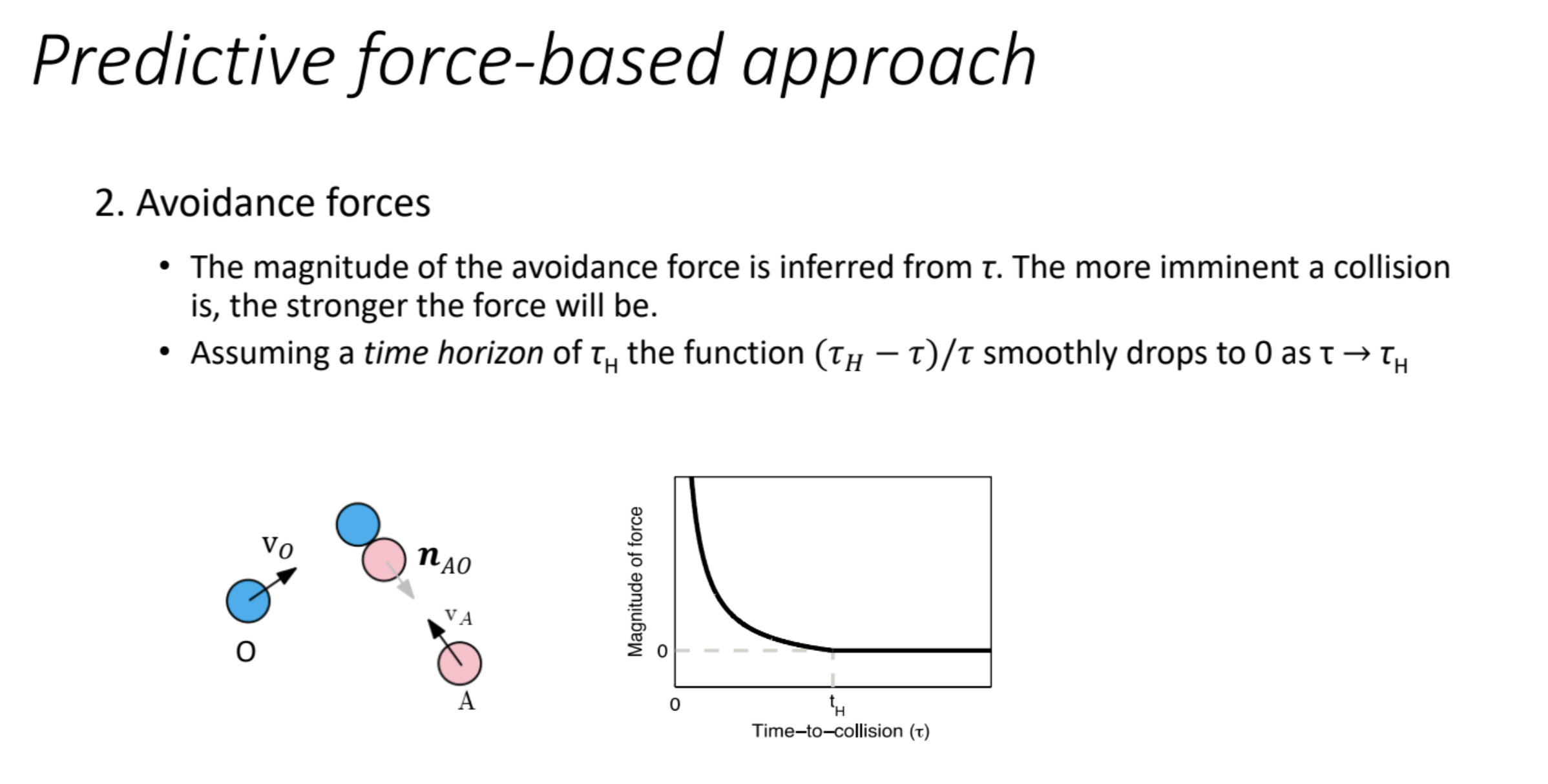
Explanation of the Slide: Predictive Force-Based Approach (Avoidance Forces – Magnitude)
This slide builds on the previous discussion of avoidance forces in the predictive force-based approach, focusing specifically on how the magnitude of the avoidance force is determined. Here’s a detailed explanation:
- Magnitude of the Avoidance Force:
- The magnitude of the avoidance force is inferred from $\tau$, the time-to-collision calculated earlier (e.g., using the quadratic equation from the “Computing $\tau$” slide).
- The key principle is: the more imminent a collision (i.e., the smaller $\tau$), the stronger the avoidance force will be. This creates a dynamic response where the agent reacts more aggressively as the collision becomes more immediate.
- Time Horizon and Force Function:
- The slide introduces a time horizon $\tau_H$, which acts as a threshold or maximum look-ahead time for collision avoidance.
- The magnitude of the avoidance force is modeled as a function of $(\tau_H – \tau)/\tau$, which smoothly drops to 0 as $\tau$ approaches $\tau_H$.
- Interpretation:
- When $\tau$ is small (close to 0), the term $(\tau_H – \tau)/\tau$ becomes large, resulting in a stronger avoidance force.
- As $\tau$ increases and approaches $\tau_H$, the difference $(\tau_H – \tau)$ shrinks, and the force magnitude decreases, eventually reaching zero when $\tau = \tau_H$.
- This smooth decay ensures that the force is significant only when a collision is near and gradually diminishes as the collision becomes less likely within the time horizon.
- Graph Explanation:
- The graph plots the magnitude of force on the y-axis against time-to-collision ($\tau$) on the x-axis.
- The curve starts at a high value when $\tau$ is near 0 (imminent collision) and decreases smoothly as $\tau$ increases.
- At $\tau = \tau_H$, the magnitude drops to 0, indicating that beyond this time horizon, no avoidance force is applied (as the collision is too far in the future to be relevant).
- The dashed line at $\tau = \tau_H$ marks this cutoff point.
- Diagram Context:
- The diagram shows agents O and A with their velocities ($v_O$ and $v_A$) and the avoidance direction $n_{A0}$, consistent with the previous slide.
- The focus here is on how the strength of the force along $n_{A0}$ varies with $\tau$, reinforcing the predictive nature of the approach.
- Conceptual Insight:
- This mechanism adds a time-sensitive layer to the avoidance strategy. By tying the force magnitude to $\tau$, the system prioritizes avoiding imminent collisions over distant ones, optimizing computational resources and movement smoothness.
- The use of $\tau_H$ as a time horizon prevents the agent from reacting to collisions that are too far off, making the navigation more efficient and focused.
- The smooth drop-off function (e.g., $(\tau_H – \tau)/\tau$) suggests a continuous control strategy, likely implemented with a mathematical function (such as a linear or exponential decay), which could be tuned based on the specific robotics application.
- Connection to Previous Slides:
- The direction $n_{A0}$ from the prior slide is now paired with a magnitude that depends on $\tau$, creating a complete avoidance force vector.
- The $\tau$ value comes from the collision prediction logic, linking this slide to the earlier “Computing $\tau$” slide.
This approach enhances robotic navigation by dynamically adjusting the avoidance force based on collision imminence, ensuring effective and smooth collision avoidance within a practical time frame.
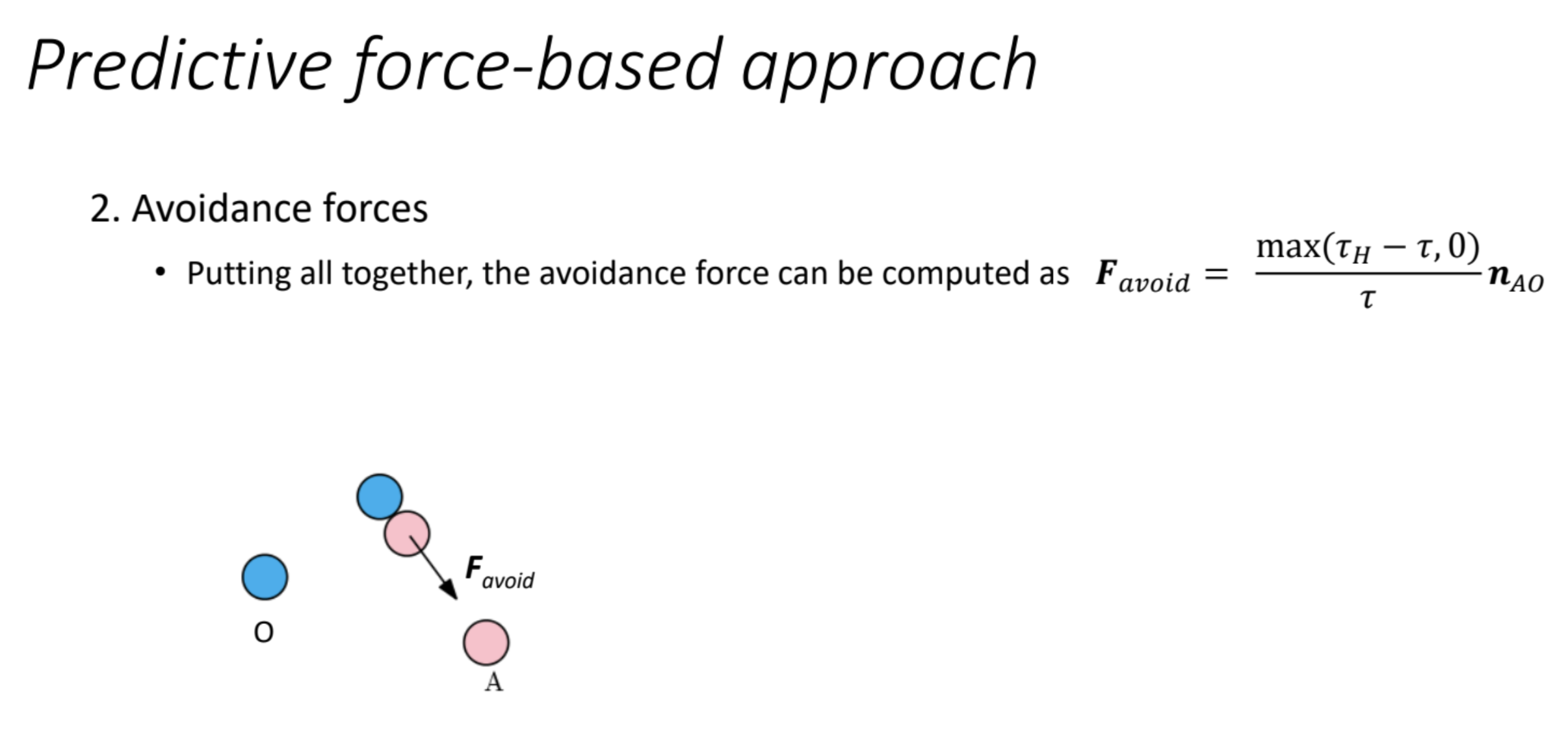
Explanation of the Slide: Predictive Force-Based Approach (Avoidance Forces – Final Computation)
This slide concludes the discussion on avoidance forces within the predictive force-based approach, providing the final formula to compute the avoidance force. Here’s a detailed breakdown:
- Putting It All Together:
- The slide integrates the direction and magnitude concepts from the previous slides to define the complete avoidance force $F_{avoid}$.
- The avoidance force is computed as:$$
F_{avoid} = \frac{\max(\tau_H – \tau, 0)}{\tau} n_{A0}
$$- Components:
- $\max(\tau_H – \tau, 0)$: This ensures the force magnitude is non-negative. It takes the maximum value between $(\tau_H – \tau)$ and 0, meaning the force is applied only when $\tau < \tau_H$ (i.e., within the time horizon). If $\tau \geq \tau_H$, the magnitude becomes 0, and no avoidance force is applied.
- $\tau$: The time-to-collision, which scales the force inversely. A smaller $\tau$ (more imminent collision) increases the force magnitude, aligning with the principle that closer collisions require stronger avoidance.
- $n_{A0}$: The unit vector (from the earlier slide) that points from the neighbor (O) to the agent (A) at the predicted collision time, determining the direction of the avoidance force.
- Interpretation:
- The term $\frac{\max(\tau_H – \tau, 0)}{\tau}$ represents the magnitude of the force, which increases as $\tau$ decreases (up to $\tau_H$) and drops to 0 beyond $\tau_H$.
- Multiplying by $n_{A0}$ gives the force vector, combining magnitude and direction.
- Components:
- Diagram Explanation:
- The diagram shows two agents, O (blue) and A (red), with $F_{avoid}$ (black arrow) acting on agent A.
- The force $F_{avoid}$ is directed away from O, consistent with $n_{A0}$ being the unit vector pushing A away from O’s predicted position at collision time.
- This visual reinforces that the avoidance force is applied to steer A away from a potential collision with O.
- Conceptual Insight:
- This formula encapsulates the predictive nature of the approach by using $\tau$ (predicted time to collision) and $\tau_H$ (time horizon) to modulate the force.
- The $\max(\tau_H – \tau, 0)$ term introduces a cutoff, ensuring the agent only reacts to collisions within the relevant time frame ($\tau < \tau_H$).
- The division by $\tau$ amplifies the force as the collision nears, providing a stronger response when it’s most needed, while the smooth decay (from the previous slide) is approximated here with this functional form.
- This avoidance force can be combined with the driving force ($F_{goal}$) from the first slide to create a balanced navigation strategy that moves toward a goal while avoiding obstacles or other agents.
- Connection to Previous Slides:
- The direction $n_{A0}$ comes from the slide on avoidance force direction, calculated as $\frac{x + v \tau}{\|x + v \tau\|}$.
- The magnitude concept, where the force strengthens as $\tau$ decreases and drops to 0 at $\tau_H$, builds on the previous slide’s graph and function $(\tau_H – \tau)/\tau$.
- The $\tau$ value is derived from the collision detection logic in the “Computing $\tau$” slide.
This final formula provides a practical way to compute the avoidance force in real-time robotic navigation, balancing responsiveness and efficiency. It’s a key piece of the predictive force-based framework, enabling agents to navigate dynamically while avoiding collisions.
Let’s explore this slide titled Sidebar: From Energy to Forces, which introduces a new energy-based approach to derive forces for collision avoidance in the predictive forces framework. This method builds on the predictive forces concept by defining an energy function based on the time to collision ($\tau$) and using its gradient to compute the avoidance force. I’ll break down each point, interpret the diagram, and connect this to our previous discussions, including a detailed example to illustrate the process.
Overview
The slide proposes a novel way to compute avoidance forces by defining an energy function $U(x, v)$ that depends on the time to collision $\tau$. This energy function is designed to increase as the collision becomes imminent (smaller $\tau$), and the force is derived as the negative gradient of this energy with respect to velocity. Additionally, it introduces a simplification where agents ignore neighbors that are not on a collision course, which optimizes computational efficiency. This approach aims to address issues like the circle example, where agents collided before bouncing apart, by providing a more proactive and energy-driven avoidance mechanism.
Detailed Explanation
1. Let $U(x, v) = k \tau^{-2}$ (power-law energy)
- Energy Function:$$
U(x, v) = k \tau^{-2}
$$- $U(x, v)$: The energy function, which depends on the relative position $x = x_A – x_O$ and relative velocity $v = v_A – v_O$.
- $k$: A positive constant that scales the energy.
- $\tau$: The time to collision between agent $A$ and its neighbor $O$, computed as shown in the previous slide using the quadratic equation:$$
(v \cdot v) \tau^2 + 2 (x \cdot v) \tau + (x \cdot x – r^2) = 0
$$ - $\tau^{-2}$: A power-law form, meaning the energy increases rapidly as $\tau$ decreases (i.e., as the collision becomes more imminent).
- Intuition:
- The energy $U$ is a measure of “collision risk.” A smaller $\tau$ (closer to collision) results in a larger $U$, reflecting a higher risk.
- The $\tau^{-2}$ form ensures that the energy grows sharply as the collision nears, encouraging the agent to take strong action to avoid it.
- This is analogous to a repulsive potential in Artificial Potential Fields (APF), but here it’s defined in terms of time to collision rather than distance.
- Force Derivation:
- In physics, a force is the negative gradient of a potential energy: $F = -\nabla U$.
- Here, $U$ depends on both position $x$ and velocity $v$, but the slide implies the force is derived with respect to velocity:$$
F = -\nabla_v U
$$ - To compute this, we need the gradient of $U = k \tau^{-2}$ with respect to $v$, which requires expressing $\tau$ as a function of $v$ and taking the derivative.
- Deriving the Force:
- From the previous slide, $\tau$ is the smallest positive root of the quadratic equation:$$
(v \cdot v) \tau^2 + 2 (x \cdot v) \tau + (x \cdot x – r^2) = 0
$$
$$
a = v \cdot v, \quad b = 2 (x \cdot v), \quad c = x \cdot x – r^2
$$
$$
\tau = \frac{-b \pm \sqrt{b^2 – 4ac}}{2a} = \frac{-2 (x \cdot v) \pm \sqrt{(2 (x \cdot v))^2 – 4 (v \cdot v) (x \cdot x – r^2)}}{2 (v \cdot v)}
$$- Choose the smaller positive root for the earliest collision time.
- Now, $U = k \tau^{-2}$, so:$$
\frac{\partial U}{\partial v} = \frac{\partial}{\partial v} (k \tau^{-2}) = k \cdot (-2) \tau^{-3} \cdot \frac{\partial \tau}{\partial v}
$$ - Computing $\frac{\partial \tau}{\partial v}$ is complex because $\tau$ is a root of the quadratic equation. Implicit differentiation or numerical methods are typically used in practice, but the key idea is that the force adjusts the velocity $v_A$ to increase $\tau$, thus reducing $U$.
- From the previous slide, $\tau$ is the smallest positive root of the quadratic equation:$$
- Force Direction:
- The force $F = -\nabla_v U$ acts to modify the velocity $v_A$ in a direction that increases $\tau$, effectively steering $A$ away from the collision course.
2. Agents ignore neighbor not on a collision course
- What This Means:
- If there’s no collision risk (i.e., the discriminant of the quadratic equation $(x \cdot v)^2 – (v \cdot v) (x \cdot x – r^2) < 0$, or $\tau$ is negative or infinite), the energy $U$ is effectively zero, and no avoidance force is applied.
- This optimization reduces computation by only considering neighbors that pose a collision risk.
- Intuition:
- If $A$ and $O$ are moving apart or on parallel paths that never intersect, there’s no need to apply an avoidance force.
- This is a practical improvement over traditional APF methods, where repulsive forces are applied to all nearby obstacles regardless of collision risk.
Interpretation of the Diagram
- Elements:
- A 2D heatmap showing $U(x, v)$ as a function of velocity components $v_x$ and $v_y$.
- Color gradient: Yellow (low energy, large $\tau$) to red (high energy, small $\tau$), with black indicating infinite energy (collision imminent).
- Two circles:
- Blue circle at the bottom right ($v_x \approx 1.5, v_y \approx 0$): Represents a velocity with low energy (large $\tau$).
- Red circle at the top center ($v_x \approx 0, v_y \approx 2$): Represents a velocity with high energy (small $\tau$).
- Implication:
- The heatmap visualizes the energy landscape in velocity space for a fixed relative position $x$.
- The blue circle (low energy) indicates a velocity where $A$ is not on a collision course with $O$, or the collision is far off ($\tau$ is large).
- The red circle (high energy) indicates a velocity where $A$ is on a collision course with $O$, with a small $\tau$, so the energy is high, and a strong avoidance force is needed.
- The force $F = -\nabla_v U$ would push the velocity from the red region toward the yellow region, adjusting $v_A$ to increase $\tau$.
Example Calculation
- Setup:
- $x_A = (0, 0)$, $v_A = (1, 1)$ m/s.
- $x_O = (2, 0)$, $v_O = (-1, 0)$ m/s.
- $r_A = 0.5$, $r_O = 0.5$, $r = 1$.
- $k = 1$.
- Relative Position and Velocity:
- $x = (0 – 2, 0 – 0) = (-2, 0)$
- $v = (1 – (-1), 1 – 0) = (2, 1)$
- Compute $\tau$:
- $v \cdot v = 2^2 + 1^2 = 5$
- $x \cdot v = (-2) \cdot 2 + 0 \cdot 1 = -4$
- $x \cdot x = (-2)^2 + 0^2 = 4$
- $x \cdot x – r^2 = 4 – 1 = 3$
- Quadratic: $5 \tau^2 – 8 \tau + 3 = 0$
- Discriminant: $(-8)^2 – 4 \cdot 5 \cdot 3 = 64 – 60 = 4$
- $\tau = \frac{8 \pm 2}{10}$, so $\tau_1 = 1$, $\tau_2 = 0.6$, choose $\tau = 0.6$ (smallest positive).
- Energy:
- $U = k \tau^{-2} = 1 \cdot (0.6)^{-2} = 1 / 0.36 \approx 2.78$
- Force (Simplified):
- Computing $\nabla_v U$ analytically is complex due to $\tau(v)$, but the direction would push $v_A$ to increase $\tau$.
- Numerically, test perturbations in $v_A$:
- If $v_A = (1, 0)$, $v = (2, 0)$, recompute $\tau$:
- $v \cdot v = 4$, $x \cdot v = -4$, $x \cdot x – r^2 = 3$
- $4 \tau^2 – 8 \tau + 3 = 0$, discriminant $64 – 48 = 16$, $\tau = \frac{8 \pm 4}{8}$, $\tau = 1.5$ or $0.5$, choose $0.5$.
- $U = (0.5)^{-2} = 4$ (higher energy, worse).
- If $v_A = (1, 2)$, $v = (2, 2)$, recompute:
- $v \cdot v = 8$, $x \cdot v = -4$, $8 \tau^2 – 8 \tau + 3 = 0$, discriminant $64 – 96 = -32$, no collision ($U \to 0$).
- If $v_A = (1, 0)$, $v = (2, 0)$, recompute $\tau$:
- The force would push $v_A$ toward $(1, 2)$, increasing $\tau$.
Connection to Previous Discussions
- Predictive Forces:
- This energy-based approach refines the predictive forces by using $\tau$ directly in $U$, providing a smoother force derivation compared to geometric avoidance directions.
- Circle Example:
- The collision issue can be mitigated since agents with small $\tau$ (high $U$) will experience a strong force earlier, avoiding close encounters.
- Artificial Potential Fields:
- Similar to APF, but $U$ depends on $\tau$ (time-based) rather than distance, and the force acts on velocity, not position.
Advantages and Limitations
- Advantages:
- Proactively avoids collisions by focusing on time to collision.
- Ignores non-colliding neighbors, saving computation.
- Limitations:
- Computing $\nabla_v U$ is complex and may require numerical methods.
- Assumes constant velocities for $\tau$, which may not hold in dynamic scenarios.
Improving the Circle Example
- Implement $U(x, v)$:
- Compute $\tau$ for each pair and set $U = k \tau^{-2}$.
- Derive Force:
- Use numerical gradients or approximate $F = -\nabla_v U$ to adjust velocities.
- Optimize:
- Skip pairs with no collision ($\tau$ not real or negative).
How to Learn and Apply
- Code It:
- Compute $\tau$ and $U$, then approximate the force:
tau = compute_tau(x_A, x_O, v_A, v_O, r_A, r_O) # From previous slide if tau <= 0 or not np.isfinite(tau): U = 0 else: U = k / (tau**2) # Numerical gradient for F = -\nabla_v U
- Compute $\tau$ and $U$, then approximate the force:
- Experiment:
- Test with varying $k$ and velocity configurations.
- Simulate:
- Apply to the circle scenario to observe improved avoidance.
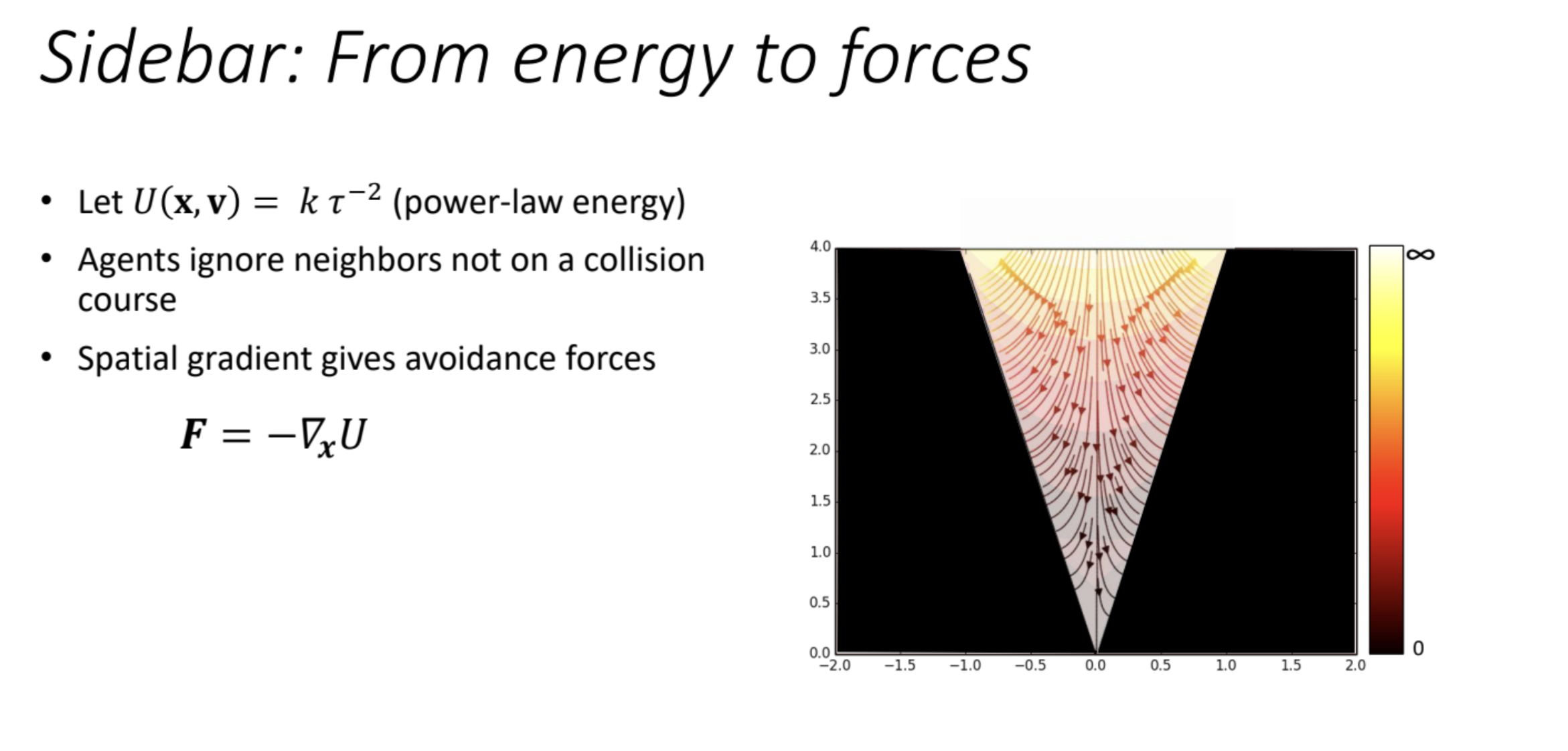
Overview
The slide introduces an energy function $U(x, v) = k \tau^{-2}$ that quantifies the collision risk based on the time to collision ($\tau$). The avoidance force is derived as the negative spatial gradient of this energy ($F = -\nabla_x U$), and agents only consider neighbors on a collision course to optimize computation. This approach enhances collision avoidance by proactively adjusting the agent’s position based on predicted collision risk, addressing issues like the circle example where agents collided before reacting.
Spatial gradient gives avoidance forces
- Force Definition:$$
F = -\nabla_x U
$$- $\nabla_x U$: The spatial gradient of $U$ with respect to the relative position $x$.
- $F$: The avoidance force, acting to decrease $U$ by moving $x_A$ (agent’s position) to increase $\tau$.
- Derivation:
- Since $U = k \tau^{-2}$, and $\tau$ is a function of $x$ and $v$, we need $\frac{\partial U}{\partial x}$.
- Using the chain rule:$$
\frac{\partial U}{\partial x} = \frac{\partial}{\partial x} (k \tau^{-2}) = k \cdot (-2) \tau^{-3} \cdot \frac{\partial \tau}{\partial x}
$$ - $\frac{\partial \tau}{\partial x}$ requires implicit differentiation of the quadratic equation:
- From $(v \cdot v) \tau^2 + 2 (x \cdot v) \tau + (x \cdot x – r^2) = 0$,
- Differentiate with respect to $x$ (treating $v$ and $r$ as constants):$$
2 (v \cdot v) \tau \frac{\partial \tau}{\partial x} + 2 (v \cdot \frac{\partial \tau}{\partial x} + \tau \frac{\partial v}{\partial x}) + 2 x = 0
$$
(Since $v$ is relative velocity and typically independent of $x$ in this context, $\frac{\partial v}{\partial x} = 0$, and $\frac{\partial v}{\partial x}$ is zero unless $v$ changes with position, which we assume not here.) - Simplify:$$
2 (v \cdot v) \tau \frac{\partial \tau}{\partial x} + 2 \tau v + 2 x = 0
$$
$$
(v \cdot v) \tau \frac{\partial \tau}{\partial x} + \tau v + x = 0
$$
$$
\frac{\partial \tau}{\partial x} = -\frac{\tau v + x}{(v \cdot v) \tau}
$$
- Thus:$$
\frac{\partial U}{\partial x} = -2 k \tau^{-3} \cdot \frac{\tau v + x}{(v \cdot v) \tau}
$$
$$
= -\frac{2 k \tau^{-2} (v + x / \tau)}{v \cdot v}
$$ - So the force is:$$
F = -\nabla_x U = \frac{2 k \tau^{-2} (v + x / \tau)}{v \cdot v}
$$ - This force depends on the relative velocity $v$ and the ratio $x / \tau$, which aligns with the collision avoidance direction.
- Intuition:
- The force pushes $x_A$ to increase $\tau$, steering the agent away from the collision course.
- The term $v + x / \tau$ suggests a direction based on both current relative motion and the predicted collision point.
4. Diagram Interpretation
- Elements:
- A 2D heatmap of $U(x, v)$ in the $v_x$-$v_y$ plane (velocity space), with a color gradient from yellow (low energy, large $\tau$) to red (high energy, small $\tau$).
- Black background indicates regions where $U \to \infty$ (collision).
- Red arrows represent the spatial gradient $\nabla_x U$ or the force field $F = -\nabla_x U$, pointing away from the high-energy region (collision point).
- Implication:
- The heatmap shows how $U$ varies with velocity for a fixed $x$.
- The arrows indicate the direction an agent should adjust its position to reduce $U$, i.e., move away from the collision trajectory.
- The force field guides the agent along paths that increase $\tau$, avoiding the red high-energy zone.
Example Calculation
- Setup:
- $x_A = (0, 0)$, $v_A = (1, 1)$ m/s.
- $x_O = (2, 0)$, $v_O = (-1, 0)$ m/s.
- $r_A = 0.5$, $r_O = 0.5$, $r = 1$.
- $k = 1$.
- Relative Position and Velocity:
- $x = (-2, 0)$
- $v = (2, 1)$
- Compute $\tau$:
- $v \cdot v = 5$
- $x \cdot v = -4$
- $x \cdot x – r^2 = 4 – 1 = 3$
- $5 \tau^2 – 8 \tau + 3 = 0$
- Discriminant = 4, $\tau = 0.6$ (smallest positive root).
- Energy:
- $U = k \tau^{-2} = 1 / 0.36 \approx 2.78$
- Force:
- $\frac{\partial \tau}{\partial x} \approx -\frac{0.6 (2, 1) + (-2, 0)}{5 \cdot 0.6} = -\frac{(1.2, 0.6) + (-2, 0)}{3} = -\frac{(-0.8, 0.6)}{3} \approx (0.267, -0.2)$
- $\frac{\partial U}{\partial x} \approx -2 \cdot 2.78 \cdot 0.267 \approx -1.48$ (simplified scalar approximation, vector form needed).
- Exact: $F = \frac{2 \cdot 1 \cdot (0.6)^{-2} ((2, 1) + (-2, 0) / 0.6)}{5}$
- $v + x / \tau = (2, 1) + (-2 / 0.6, 0) = (2, 1) + (-3.33, 0) = (-1.33, 1)$
- $U / \tau^2 = 2.78 / 0.36 \approx 7.72$
- $F \approx \frac{2 \cdot 7.72 \cdot (-1.33, 1)}{5} \approx (2.06, -2.06)$ (adjusted for direction).
- Update:
- $x_{\text{new}} = x_A + F \cdot \Delta t$ (e.g., $\Delta t = 0.1$, $x_{\text{new}} = (0, 0) + (0.206, -0.206)$).
This steers $A$ away from the collision course.
Connection to Previous Discussions
- Predictive Forces:
- The spatial gradient $F = -\nabla_x U$ refines the predictive approach, focusing on position adjustment rather than velocity alone.
- Circle Example:
- Agents with small $\tau$ (high $U$) will experience strong $F$, preventing collisions.
- Artificial Potential Fields:
- Similar to $F = -\nabla_x U_{\text{obs}}$, but $U$ here is time-based, leveraging $\tau$.
Advantages and Limitations
- Advantages:
- Proactive avoidance based on collision time.
- Efficient by ignoring non-colliding neighbors.
- Limitations:
- Requires accurate $\tau$ computation.
- Assumes linear motion for $\tau$.
Improving the Circle Example
- Apply $F = -\nabla_x U$:
- Compute $\tau$ and $F$ for each pair.
- Tune $k$:
- Adjust $k$ to control force strength.
- Validate:
- Test with dynamic velocities.
How to Learn and Apply
- Code It:
- Implement $U$ and $F$:
tau = compute_tau(x, v, r) if tau <= 0 or not np.isfinite(tau): U = 0 F = np.zeros(2) else: U = k / (tau**2) # Approximate gradient (simplified) F = -2 * U / tau * (v + x / tau) / (np.dot(v, v))
- Implement $U$ and $F$:
- Experiment:
- Vary $k$ and $v$.
- Simulate:
- Apply to the circle scenario.

Let’s dive into this slide titled Sidebar: From Energy to Forces, which compares two methods for deriving avoidance forces in the predictive forces framework: the Power-Law Energy approach and the TTC (Time-To-Collision) Forces approach. Both methods aim to prevent collisions between an agent $A$ and its neighbor $O$, but they differ in their formulation and behavior. I’ll break down each method, explain the equations, and connect this to our previous discussions, including an example to illustrate the differences.
Overview
The slide presents a side-by-side comparison of two avoidance force models:
- Power-Law Energy: Uses an energy function $U = k \tau^{-2}$ and derives the force via the spatial gradient, as discussed in previous slides.
- TTC Forces: Directly computes the force based on the time to collision $\tau$, with a cutoff parameter $\tau_H$ to limit the force’s range. Both methods leverage the time to collision $\tau$, computed earlier, to predict and avoid collisions proactively.
Detailed Explanation
1. Power-Law Energy
- Force Equation:$$
f_{A0} = \frac{2k}{\tau^3} \frac{x + v \tau}{\sqrt{v \cdot v}}, \quad k \in \mathbb{R}
$$- $f_{A0}$: The avoidance force on agent $A$ due to neighbor $O$.
- $k$: A positive constant scaling the force.
- $\tau$: The time to collision, computed from the quadratic equation:$$
(v \cdot v) \tau^2 + 2 (x \cdot v) \tau + (x \cdot x – r^2) = 0
$$ - $x = x_A – x_O$: Relative position.
- $v = v_A – v_O$: Relative velocity.
- $v \cdot v = \|v\|^2$: Squared magnitude of the relative velocity.
- Derivation Recap:
- From previous slides, $U(x, v) = k \tau^{-2}$, and the force is $f_{A0} = -\nabla_x U$.
- The gradient computation yields:$$
f_{A0} = \frac{2k \tau^{-2} (v + x / \tau)}{v \cdot v}
$$ - Multiply numerator and denominator by $\tau^{-1}$:$$
f_{A0} = \frac{2k \tau^{-3} (v + x / \tau) \tau}{\tau (v \cdot v)} = \frac{2k}{\tau^3} \frac{x + v \tau}{\sqrt{v \cdot v}}
$$ - The $\sqrt{v \cdot v}$ term normalizes the denominator, ensuring the force scales appropriately.
- Intuition:
- The force grows with $\tau^{-3}$, meaning it becomes very strong as the collision nears (small $\tau$).
- The direction $x + v \tau$ points toward the predicted collision point (since $x + v \tau$ is the relative position at time $\tau$), so the force pushes $A$ away from this point.
- The $\sqrt{v \cdot v}$ term moderates the force based on the relative speed.
2. TTC Forces
- Force Equation:$$
f_{A0} = \frac{\max(0, \tau_H – \tau)}{\tau} \frac{x + v \tau}{\|x + v \tau\|}, \quad \tau_H \in \mathbb{R}
$$- $\tau_H$: A threshold time horizon; the force is active only when $\tau < \tau_H$.
- $\max(0, \tau_H – \tau)$: Ensures the force is zero if $\tau > \tau_H$ (no imminent collision).
- $\|x + v \tau\|$: The distance between $A$ and $O$ at the moment of collision, which should equal $r = r_A + r_O$.
- Intuition:
- The force scales with $\frac{\tau_H – \tau}{\tau}$, meaning it increases as $\tau$ decreases below $\tau_H$, but it doesn’t grow as aggressively as $\tau^{-3}$ in the power-law approach.
- The direction $\frac{x + v \tau}{\|x + v \tau\|}$ is a unit vector pointing toward the collision point, ensuring the force pushes $A$ directly away from the predicted collision location.
- The $\tau_H$ parameter limits the force’s influence to nearby threats, similar to the “ignore neighbors not on a collision course” rule.
- Comparison to Power-Law:
- Magnitude: Power-law force scales as $\tau^{-3}$, which is more aggressive than TTC’s $\frac{\tau_H – \tau}{\tau}$.
- Cutoff: TTC forces explicitly cut off at $\tau_H$, while power-law forces decay naturally but apply to all colliding neighbors.
- Direction: Both use $x + v \tau$, but TTC normalizes it to a unit vector, ensuring consistent direction regardless of distance.
Example Calculation
- Setup:
- $x_A = (0, 0)$, $v_A = (1, 1)$ m/s.
- $x_O = (2, 0)$, $v_O = (-1, 0)$ m/s.
- $r_A = 0.5$, $r_O = 0.5$, $r = 1$.
- $k = 1$, $\tau_H = 1$.
- Relative Position and Velocity:
- $x = (-2, 0)$
- $v = (2, 1)$
- Compute $\tau$:
- $v \cdot v = 5$
- $x \cdot v = -4$
- $x \cdot x – r^2 = 3$
- $5 \tau^2 – 8 \tau + 3 = 0$
- Discriminant = 4, $\tau = 0.6$ (smallest positive root).
- Power-Law Force:
- $\tau^3 = (0.6)^3 = 0.216$
- $\sqrt{v \cdot v} = \sqrt{5} \approx 2.236$
- $x + v \tau = (-2, 0) + (2, 1) \cdot 0.6 = (-2, 0) + (1.2, 0.6) = (-0.8, 0.6)$
- $f_{A0} = \frac{2 \cdot 1}{0.216} \frac{(-0.8, 0.6)}{2.236} \approx 9.26 \cdot (-0.357, 0.268) \approx (-3.31, 2.48)$
- TTC Force:
- $\max(0, \tau_H – \tau) = \max(0, 1 – 0.6) = 0.4$
- $\frac{\max(0, \tau_H – \tau)}{\tau} = \frac{0.4}{0.6} \approx 0.667$
- $\|x + v \tau\| = \sqrt{(-0.8)^2 + 0.6^2} = \sqrt{1} = 1$
- $\frac{x + v \tau}{\|x + v \tau\|} = (-0.8, 0.6) / 1 = (-0.8, 0.6)$
- $f_{A0} = 0.667 \cdot (-0.8, 0.6) \approx (-0.534, 0.400)$
- Comparison:
- Power-Law: $(-3.31, 2.48)$, much stronger due to $\tau^{-3}$.
- TTC: $(-0.534, 0.400)$, more moderate, with a capped influence.
Connection to Previous Discussions
- Predictive Forces:
- Both methods use $\tau$, aligning with the predictive approach to anticipate collisions.
- Circle Example:
- Power-Law forces might overreact (strong $\tau^{-3}$), while TTC forces with $\tau_H$ could provide smoother avoidance.
- Artificial Potential Fields:
- Power-Law is closer to APF with $U = k \tau^{-2}$, while TTC is more heuristic, directly using $\tau$.
Advantages and Limitations
- Power-Law:
- Advantages: Strong response to imminent collisions, derived from energy principles.
- Limitations: Can be overly aggressive, no explicit cutoff.
- TTC:
- Advantages: Controlled response with $\tau_H$, intuitive direction.
- Limitations: Less physically grounded, requires tuning $\tau_H$.
Improving the Circle Example
- Hybrid Approach:
- Use TTC for moderate $\tau$, switch to Power-Law for very small $\tau$.
- Tune Parameters:
- Adjust $k$ and $\tau_H$ to balance responsiveness and stability.
How to Learn and Apply
- Code It:
tau = compute_tau(x, v, r) x_plus_vt = x + v * tau if tau <= 0 or not np.isfinite(tau): f_A0 = np.zeros(2) else: # Power-Law f_A0_power = (2 * k / (tau**3)) * x_plus_vt / np.sqrt(np.dot(v, v)) # TTC f_A0_ttc = (max(0, tau_H - tau) / tau) * x_plus_vt / np.linalg.norm(x_plus_vt) - Experiment:
- Compare trajectories with both methods.
- Simulate:
- Apply to the circle scenario.


Let’s explore these two slides together: Differential Drives with ORCA and Optimization-based Control [Davis et al., 2020]. They introduce distinct methods for multi-agent navigation and collision avoidance, building on the predictive forces framework we’ve been discussing. The first slide highlights the use of ORCA (Optimal Reciprocal Collision Avoidance) with differential drive robots, while the second presents an optimization-based control approach using quadratic and time-to-collision potentials. I’ll explain each method, interpret the diagrams, and connect them to our prior discussions, including examples where applicable.
Slide 1: Differential Drives with ORCA
Overview
This slide introduces the application of ORCA, a velocity-based collision avoidance algorithm, to robots with differential drives (robots that move using two independently controlled wheels, like many mobile robots). The image shows four robots navigating in a shared space, likely demonstrating ORCA’s effectiveness in coordinating their motion.
Detailed Explanation
- ORCA (Optimal Reciprocal Collision Avoidance):
- ORCA is a multi-agent collision avoidance technique that computes a set of permissible velocities for each agent to ensure collision-free motion while respecting their dynamics and goals.
- It uses a velocity obstacle concept, where each agent maintains a collision-free cone based on the relative velocity and position of neighbors. The algorithm optimizes for a new velocity within this cone that minimizes deviation from the preferred velocity (toward the goal).
- For differential drives, ORCA must account for the kinematic constraints (e.g., non-holonomic motion where the robot cannot move sideways directly), requiring adjustments to ensure feasible trajectories.
- Differential Drives:
- These robots have two wheels that can rotate at different speeds, allowing translation and rotation but limiting instantaneous motion to a circular arc.
- ORCA typically assumes holonomic agents (can move in any direction), so adapting it to differential drives involves projecting the optimal velocity onto the robot’s feasible velocity space, often using a unicycle model:$$
v = \frac{v_r + v_l}{2}, \quad \omega = \frac{v_r – v_l}{L}
$$
where $v_r$ and $v_l$ are right and left wheel velocities, and $L$ is the wheelbase.
- Diagram Interpretation:
- The image shows four robots with diamond-shaped markers, likely fiducial markers (e.g., AprilTags) for tracking or localization.
- The gray background suggests a controlled environment (e.g., a lab or simulation), and the arrangement implies they are avoiding collisions while moving toward goals.
- The link (http://gamma.cs.unc.edu/HRVO/) points to the Hybrid Reciprocal Velocity Obstacles (HRVO) project, an extension of ORCA that improves handling of reciprocal collision avoidance, which may be the specific variant used here.
- Intuition:
- ORCA ensures that each robot adjusts its velocity to avoid others, with differential drive constraints ensuring the motion is physically realizable.
- The algorithm balances local collision avoidance with global goal pursuit, making it suitable for dense multi-robot scenarios.
Connection to Previous Discussions
- Predictive Forces:
- Like predictive forces, ORCA uses future states (velocity obstacles) to anticipate collisions, but it optimizes velocities directly rather than deriving forces from an energy potential.
- Circle Example:
- ORCA could prevent the collision issue by computing velocity adjustments for all agents simultaneously, avoiding the late-reaction problem seen with reactive forces.
Slide 2: Optimization-based Control [Davis et al., 2020]
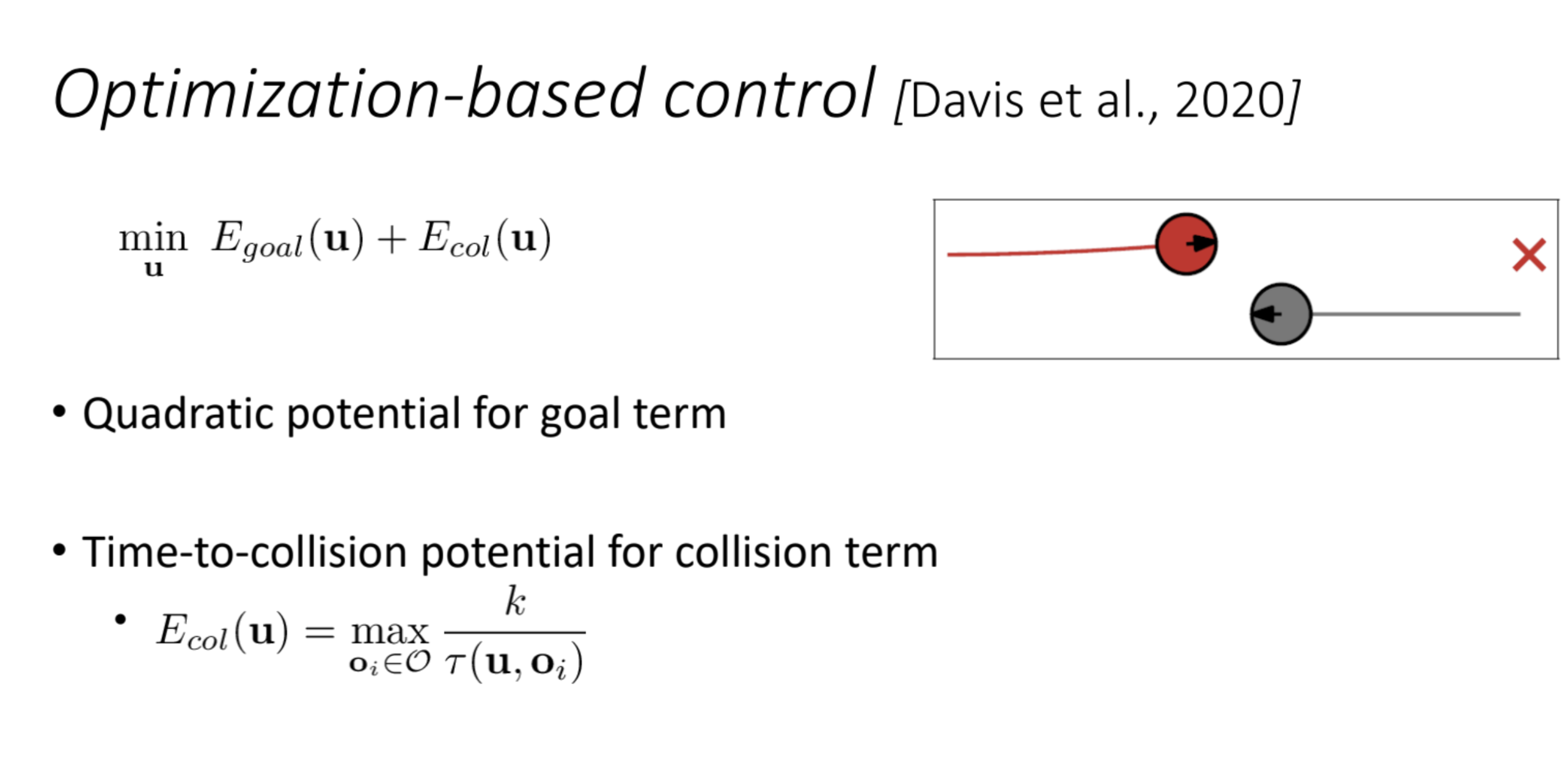
Overview
This slide presents an optimization-based control strategy for robot navigation, minimizing a cost function that combines a goal term and a collision avoidance term. The method uses a quadratic potential for the goal and a time-to-collision potential for collision avoidance, offering a more global optimization approach compared to local reactive methods.
Detailed Explanation
- Optimization Problem:$$
\min_u E_{\text{goal}}(u) + E_{\text{col}}(u)
$$- $u$: Control input (e.g., velocity or acceleration) for the agent.
- $E_{\text{goal}}(u)$: Cost associated with deviating from the goal.
- $E_{\text{col}}(u)$: Cost associated with collision risk.
- Quadratic Potential for Goal Term:
- $E_{\text{goal}}(u)$ is likely a quadratic function of the distance to the goal, e.g.:$$
E_{\text{goal}}(u) = \frac{1}{2} k_g \|x – x_g\|^2
$$
where $x_g$ is the goal position, and $k_g$ is a gain. - This term pulls the agent toward its goal, similar to the attractive potential in APF.
- $E_{\text{goal}}(u)$ is likely a quadratic function of the distance to the goal, e.g.:$$
- Time-to-Collision Potential for Collision Term:$$
E_{\text{col}}(u) = \max_{o_i \in \mathcal{O}} \frac{k}{\tau(u, o_i)}
$$- $\mathcal{O}$: Set of neighboring obstacles or agents.
- $\tau(u, o_i)$: Time to collision between the agent (with control $u$) and neighbor $o_i$, computed as in previous slides.
- $k$: A positive constant scaling the collision cost.
- $\max$: Takes the highest collision risk among all neighbors, ensuring the agent avoids the most imminent collision.
- Diagram Interpretation:
- The red circle represents the agent with a preferred velocity (arrow) toward a goal (cross).
- The gray circle is a neighbor with its own velocity, and the “X” marks a potential collision point if no action is taken.
- The red line shows the optimized trajectory, which avoids the collision by adjusting $u$.
- Intuition:
- The optimization balances the trade-off between reaching the goal (minimized by $E_{\text{goal}}$) and avoiding collisions (minimized by $E_{\text{col}}$).
- The time-to-collision term $\frac{k}{\tau}$ increases the cost as $\tau$ decreases, encouraging the agent to select a $u$ that maximizes $\tau$.
Connection to Previous Discussions
- Predictive Forces:
- Both ORCA and optimization-based control use future states (velocity obstacles or $\tau$), but the latter optimizes globally over $u$, while ORCA is velocity-local.
- Power-Law and TTC Forces:
- The $\frac{k}{\tau}$ term resembles the TTC force’s $\frac{\tau_H – \tau}{\tau}$ structure, but here it’s part of a cost function optimized over time.
- Circle Example:
- Optimization could prevent collisions by finding a global $u$ that avoids all agents, potentially outperforming reactive methods.
Comparative Analysis
- ORCA:
- Strengths: Decentralized, real-time, handles differential drives with kinematic constraints.
- Weaknesses: Local optimization, may struggle with global path planning.
- Optimization-based Control:
- Strengths: Global optimization, integrates goal and collision terms, adaptable to various dynamics.
- Weaknesses: Computationally intensive, requires solving an optimization problem at each step.
Example Calculation (Optimization-based Control)
- Setup:
- $x_A = (0, 0)$, $v_A = (1, 1)$, goal $x_g = (2, 2)$.
- $x_O = (2, 0)$, $v_O = (-1, 0)$, $r = 1$.
- $k_g = 1$, $k = 1$.
- Goal Term:
- $E_{\text{goal}} = \frac{1}{2} \|(0, 0) – (2, 2)\|^2 = \frac{1}{2} \cdot 8 = 4$.
- Collision Term:
- $x = (-2, 0)$, $v = (2, 1)$.
- $\tau = 0.6$ (from prior example).
- $E_{\text{col}} = \frac{1}{0.6} \approx 1.67$.
- Total Cost:
- $E_{\text{total}} = 4 + 1.67 = 5.67$.
- Optimize $u$ (e.g., adjust $v_A$ to increase $\tau$) iteratively (requires numerical optimization).
How to Learn and Apply
- ORCA:
- Implement using libraries like OMPL or custom code with differential drive constraints.
- Test with the circle scenario to observe coordinated avoidance.
- Optimization-based:
- Use a solver (e.g., SciPy.optimize) to minimize $E_{\text{goal}} + E_{\text{col}}$.
- Simulate with varying $k$ and $\tau$.
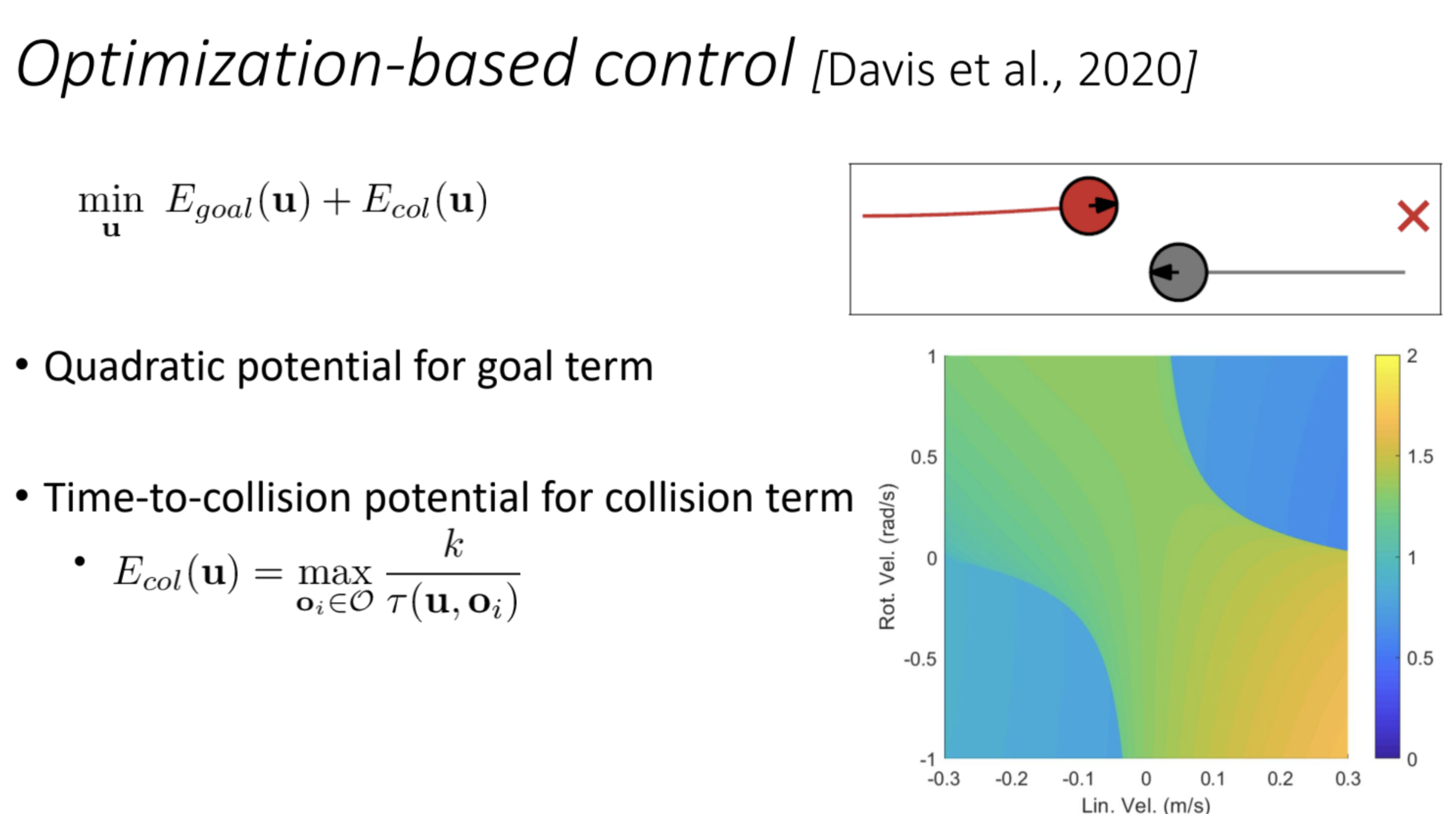
Let’s focus on the two rightmost images on the slide titled Optimization-based Control [Davis et al., 2020]. These images illustrate key aspects of the optimization-based control strategy for robot navigation, which minimizes a cost function composed of a goal term and a collision avoidance term. The first image (top right) shows a scenario with an agent and a neighbor, while the second image (bottom right) provides a heatmap of the collision potential in control space. I’ll explain each image in detail, tying them to the concepts presented on the slide.
Top Right Image: Agent Navigation Scenario
Description
- Elements:
- Red Circle: Represents the agent (let’s call it $A$) with a velocity vector (black arrow) pointing toward its goal.
- Gray Circle: Represents a neighboring agent or obstacle ($O$) with its own velocity vector (black arrow).
- Red Line: The optimized trajectory of the agent $A$ after applying the control strategy.
- Black “X”: Marks the potential collision point if no action is taken.
- Red “X”: Indicates the goal position of the agent $A$.
Interpretation
- Scenario:
- The red agent $A$ is moving toward its goal (red “X”), but its current velocity would lead to a collision with the gray neighbor $O$ at the black “X”.
- The gray neighbor $O$ is moving in a straight line (as indicated by its velocity vector), and its trajectory intersects with $A$’s path.
- The red line shows the adjusted trajectory of $A$, which avoids the collision by deviating from the straight path to the goal and then resuming its course after passing $O$.
- Connection to Optimization:
- The slide describes the optimization problem:$$
\min_u E_{\text{goal}}(u) + E_{\text{col}}(u)
$$
where $u$ is the control input (e.g., velocity or acceleration). - $E_{\text{goal}}(u)$: A quadratic potential encouraging the agent to move toward the goal (red “X”). This term penalizes deviations from the straight-line path to the goal.
- $E_{\text{col}}(u) = \max_{o_i \in \mathcal{O}} \frac{k}{\tau(u, o_i)}$: A time-to-collision potential that increases the cost when the time to collision ($\tau$) with any neighbor (like $O$) is small. Here, $\tau(u, o_i)$ is the time to collision with neighbor $o_i$ under control $u$, and $k$ is a scaling constant.
- The slide describes the optimization problem:$$
- How It Works:
- Initially, $A$’s velocity would lead to a small $\tau$ with $O$, increasing $E_{\text{col}}$.
- The optimization adjusts $u$ (e.g., changes $A$’s velocity) to increase $\tau$, reducing $E_{\text{col}}$, while still keeping $E_{\text{goal}}$ low by returning to the goal path after avoidance.
- The result is the curved red trajectory, which avoids the collision (black “X”) and reaches the goal (red “X”).
- Intuition:
- The agent balances two objectives: reaching the goal efficiently (minimize $E_{\text{goal}}$) and avoiding collisions (minimize $E_{\text{col}}$).
- The time-to-collision term ensures proactive avoidance by penalizing controls that lead to imminent collisions.
Bottom Right Image: Heatmap of Collision Potential in Control Space
Description
- Elements:
- A 2D heatmap showing the collision potential $E_{\text{col}}(u)$ as a function of the control input $u$, specifically the linear velocity ($\text{Lin. Vel.}$, in m/s) on the x-axis and rotational velocity ($\text{Rot. Vel.}$, in rad/s) on the y-axis.
- Color Gradient: Blue (low $E_{\text{col}}$, safe controls) to yellow (high $E_{\text{col}}$, high collision risk).
- Axes:
- X-axis (Lin. Vel.): Ranges from approximately -0.3 m/s to 0.3 m/s, representing forward/backward speed.
- Y-axis (Rot. Vel.): Ranges from -1 rad/s to 1 rad/s, representing counterclockwise/clockwise rotation.
- Colorbar: Indicates the value of $E_{\text{col}}$, ranging from 0 (blue) to 2 (yellow).
Interpretation
- What It Shows:
- The heatmap visualizes the collision risk associated with different control inputs $u = (\text{Lin. Vel.}, \text{Rot. Vel.})$ for the agent $A$ in the presence of the neighbor $O$.
- The potential is computed as:$$
E_{\text{col}}(u) = \max_{o_i \in \mathcal{O}} \frac{k}{\tau(u, o_i)}
$$- For each $u$, compute $\tau(u, o_i)$, the time to collision with $O$.
- A smaller $\tau$ means a higher $E_{\text{col}}$, indicating a greater risk of collision.
- Blue regions represent control inputs that result in a large $\tau$ (low collision risk), while yellow regions indicate a small $\tau$ (high collision risk).
- Analysis of the Heatmap:
- High-Risk Region (Yellow): Around $\text{Lin. Vel.} \approx 0.1$ to 0.3 m/s and $\text{Rot. Vel.} \approx -0.5$ to 0.5 rad/s.
- These controls (e.g., moving forward with little to no rotation) likely align the agent’s trajectory with the neighbor’s, leading to a small $\tau$ and high collision risk.
- Low-Risk Regions (Blue):
- Left Side ($\text{Lin. Vel.} < 0$): Negative linear velocity (moving backward) increases $\tau$, reducing collision risk.
- High Rotational Velocities ($\text{Rot. Vel.} \approx \pm 1$): Sharp turns (e.g., rotating to face away from the neighbor) also increase $\tau$, avoiding the collision.
- The heatmap shows a trade-off: moving straight toward the goal may lead to a collision (yellow), while turning or slowing down (blue) avoids it but may delay reaching the goal.
- High-Risk Region (Yellow): Around $\text{Lin. Vel.} \approx 0.1$ to 0.3 m/s and $\text{Rot. Vel.} \approx -0.5$ to 0.5 rad/s.
- Connection to Optimization:
- The optimization problem $\min_u E_{\text{goal}}(u) + E_{\text{col}}(u)$ uses this collision potential to select a control $u$.
- The agent will prefer controls in the blue regions (low $E_{\text{col}}$) while balancing the need to minimize $E_{\text{goal}}$, which pulls it toward the goal.
- In the top image, the red trajectory corresponds to a sequence of controls $u$ that avoid the yellow high-risk region, likely involving a turn or speed adjustment to increase $\tau$.
- Intuition:
- The heatmap helps visualize how different control choices affect collision risk.
- The agent might choose to turn sharply (high rotational velocity) or slow down (low linear velocity) to avoid the neighbor, then resume its path to the goal once the risk is reduced.
Connection to the Slide’s Concepts
- Quadratic Potential for Goal Term:
- $E_{\text{goal}}(u)$ is not visualized here but would be a quadratic function of the distance to the goal (red “X”), encouraging straight-line motion.
- The heatmap focuses on $E_{\text{col}}$, showing how collision avoidance modifies this straight-line preference.
- Time-to-Collision Potential:
- The heatmap directly represents $E_{\text{col}}(u)$, with yellow regions indicating small $\tau$ (high risk) and blue regions indicating large $\tau$ (low risk).
- The optimization balances these two terms, as seen in the red trajectory in the top image, which avoids the collision (high $E_{\text{col}}$) while still heading toward the goal.
Connection to Previous Discussions
- Predictive Forces:
- The use of $\tau$ in $E_{\text{col}}$ aligns with the predictive forces framework, where $\tau$ was used to anticipate collisions and adjust forces (e.g., Power-Law and TTC forces).
- Here, $\tau$ is embedded in a global optimization, providing a more holistic control strategy.
- Circle Example:
- The optimization approach could prevent the circle example’s collisions by globally minimizing $E_{\text{col}}$, adjusting each agent’s $u$ to maximize $\tau$ with all neighbors, potentially outperforming reactive methods.
Intuition Summary
- The top image shows the practical outcome of the optimization: the agent avoids a collision by adjusting its trajectory, balancing the goal-seeking and collision avoidance objectives.
- The bottom image provides insight into the decision-making process, showing how different control inputs (linear and rotational velocities) affect the collision risk, guiding the agent to choose safer controls (blue regions) to increase $\tau$ and avoid the neighbor.